Одностраничные приложения
В этой главе мы продолжаем совершенствовать свои навыки работы с Vue 3, знакомясь с одностраничными приложениями (SPA). Мы узнаем, что отличает их от обычных сайтов, и рассмотрим их ключевые характеристики.
Чтобы применить полученные знания на практике, мы создадим новую версию приложения To-Do с использованием маршрутизатора Vue Router и иной схемы взаимодействия, чем в предыдущих главах. Мы также изучим методы аутентификации на примерах кода.
К концу этой главы вы будете знать следующее:
- Как создавать SPA с помощью Vue 3
- Как организовать приложение для использования Vue Router с различными стратегиями маршрутизации
- Как переделать наше приложение To-Do с практическим применением различных паттернов
- Как реализовать различные паттерны аутентификации в SPA
Если предыдущая глава была несколько перегружена фундаментальными знаниями, то теперь мы больше сосредоточимся на практических вопросах. В связи с этим вам потребуется доступ к приложениям-примерам, чтобы разобраться с ними.
Технические требования
Код этой главы можно найти на GitHub по адресу https://github.com/PacktPublishing/Vue.js-3-Design-Patterns-and-Best-Practices/tree/main/Chapter05.
Посмотрите следующее видео, чтобы увидеть код в действии.
Что такое SPA?
Чтобы объяснить, что такое SPA, необходимо сначала объяснить, как мы взаимодействуем с World Wide Web (WWW или W3). Когда мы вводим адрес в веб-браузере, то получаем веб-страницу, отправленную веб-сервером. В самом общем виде веб-сайт представляет собой набор страниц, в основном так называемых "статических страниц".
Статические в данном контексте означают, что сервер отправляет одни и те же файлы без изменений. Это делает сайт очень быстрым и безопасным. Однако чисто статический сайт не обеспечивает большой интерактивности для конечного пользователя. Иногда это называют Web 1.0.
Серверные и браузерные скрипты позволили решить это ограничение и породили многостраничные приложения (MPA). Теперь страницы могли быть как статическими, так и динамически генерируемыми на сервере, который, в свою очередь, также мог получать вызовы новых страниц с дополнительными данными, обрабатывать их и возвращать в ответ новую страницу.
Эти новые страницы, "генерируемые на лету", получили название динамических и сделали возможным появление приложений. Благодаря этим технологиям стало возможным распространение блогов, сервисов и предприятий.
С появлением таких ключевых технологий, как асинхронные коммуникации (AJAX), более развитый JavaScript, методологии локального хранения данных, увеличение скорости сети и вычислительной мощности, мы пришли к тому, что называется Web 2.0. Теперь можно было загрузить в браузер один файл и с помощью JavaScript взять под контроль весь интерфейс и интерактивность, создавая насыщенные интерактивные приложения без генерации новых страниц на сервере.
SPA обращается к серверу только для загрузки данных, пользовательского интерфейса и т.д. по мере необходимости. Появилась возможность переносить на веб-технологии то, что было традиционными десктопными приложениями, такими как текстовые редакторы, электронные таблицы, почтовые клиенты, пакеты графического дизайна и т.д.
Хорошими примерами SPA являются Office 365, Google Docs, Photoshop online, Telegram, Discord, Netflix, YouTube и т.д. Важно отметить, что появление SPA не отменяет использование MPA и не делает их устаревшими - каждый из них полезен в определенных контекстах. Большинство блогов и новостных сайтов сегодня, по сути, являются MPA и по-прежнему составляют значительную часть Интернета.
Наиболее сложные веб-приложения сегодня включают в себя смесь MPA и SPA, работающих вместе. SPA могут даже устанавливаться как гибридные приложения на настольных и мобильных устройствах. Как это реализовать, мы увидим в главе 6, Прогрессивные Web-приложения.
Двигаясь вперёд, с развитием распределенных и децентрализованных вычислений, умных блокчейнов, технология, составляющая одностраничные веб-приложения (SPA), приобрела ещё большую актуальность. Хотя эта новая эра в развитии веб-технологий еще не полностью укоренилась, ее называют Web 3.0. В этой главе мы рассмотрим эту тему более подробно и на примерах.
Все приложения, которые мы делали до сих пор, относятся к категории SPA, даже если мы еще не использовали весь их потенциал. Vue 3 специально предназначен для создания приложений такого типа и является одной из наиболее актуальных технологий для такого подхода, наряду с React, Angular, Svelte и другими.
Но не все так радужно и сладко. Как и в любой другой технологии, в использовании SPA есть свои компромиссы. В следующей таблице мы перечислим некоторые из них:
| Преимущества | Недостатки |
|---|---|
| - Более быстрая и эффективная загрузка - Локальное кэширование для повышения производительности - Разнообразные пользовательские интерфейсы и интерактивность - Проще в разработке и тестировании, чем MPA - Более эффективное использование кода и шаблонов, с меньшим количеством сетевых взаимодействий (по сравнению с перезагрузкой всей страницы) - Высокая производительность. | - Затруднение индексации и обнаружения поисковыми системами - Увеличение сложности - Увеличение времени загрузки и замедление времени появления первых интерактивных элементов |
Таблица 5.1 - Преимущества и компромиссы для SPA.
Как видите, список преимуществ намного важнее, чем недостатков. Использование SPA следует рассматривать в тех случаях, когда приложение требует значительной интерактивности пользователя и обратной связи в реальном времени.
Теперь, когда мы лучше представляем себе, что такое SPA, давайте рассмотрим ключевую концепцию, лежащую в основе их функциональности: маршрутизатор приложения.
Vue 3 роутер
Vue - отличный фреймворк для создания SPA, но без маршрутизатора (роутера) эта задача вскоре стала бы довольно сложной. Vue router - это официальный плагин, который берет на себя навигацию по приложению и сопоставляет URL с компонентом. Это дает нам преимущества MPA. С помощью маршрутизатора мы можем сделать следующее:
- Создавать динамические маршруты к компонентам и управлять ими, при необходимости автоматически отображая параметры к пропсам
- Идентифицировать маршруты (адреса и компоненты) по имени и использовать навигацию в коде
- Динамическая загрузка компонентов при необходимости, что позволяет уменьшить размер пакета
- Создать естественный и логичный подход к навигации по сайту и разделению кода
- Управлять навигацией с помощью известных событий, до и после того, как навигация произошла
- Создание анимации перехода между страницами таким образом, который невозможен при использовании MPA
Реализация маршрутизатора Vue 3 проста и соответствует той же методологии, что и в случае с другими компонентами экосистемы. Давайте возьмем наш проект из главы 4, Композиция пользовательского интерфейса с компонентами, и модифицируем его для использования маршрутизатора Vue.
Установка
При запуске нового проекта вы могли заметить, что в меню программы установки есть возможность установить маршрутизатор Vue. Если вы не выбрали эту опцию, как мы сделали в нашем примере, то последующая установка достаточно проста. В терминале, в каталоге проекта, просто выполните следующую команду:
$ npm install vue-router@4Команда загрузит и установит зависимости, как и для любого другого пакета в каталог node_modules. Для того чтобы использовать его в нашем приложении, необходимо выполнить следующие действия:
- Создать наши маршруты.
- Связать маршруты с нашими компонентами.
- Включить роутер в наше приложение.
- Установите наши шаблоны, в которых маршрутизатор будет отображать наши компоненты.
Как и многие другие компоненты фреймворка, маршрутизатор не указывает, в каких директориях или организациях должны быть размещены ваши маршруты или компоненты. Однако существует соглашение, которое мы будем использовать и которое стало стандартом де-факто в отрасли. В папке /src создайте следующие каталоги:
/router(или/routes): Здесь будут находиться наши JavaScript-файлы с маршрутами для нашего приложения/views: В этой папке будут находиться компоненты верхнего уровня, соответствующие навигации приложения (в качестве лучшей практики)
После создания этих каталогов мы готовы приступить к модификации нашего приложения для включения навигации по маршруту. Но прежде давайте рассмотрим, чего мы хотим добиться с помощью нашего маршрутизатора.
Новое приложение To-Do
В нашем новом приложении будут повторно использоваться компоненты для отображения списка дел, но также будет предусмотрена возможность создания нескольких списков или проектов. Мы будем отображать боковую панель со всеми нашими проектами, и при их выборе список будет обновляться.
Эти проекты также будут сохраняться в браузере, чтобы мы могли вернуться к ним позже, с помощью localStorage. В результате мы получим очень простую навигацию с двумя страницами верхнего уровня (компонентами):
- Лэндинг страница, на которой мы можем создавать новые проекты
- Страница проекта, на которой мы можем работать со списком дел
Следуя этим простым предпосылкам, наше приложение в готовом виде будет выглядеть следующим образом:
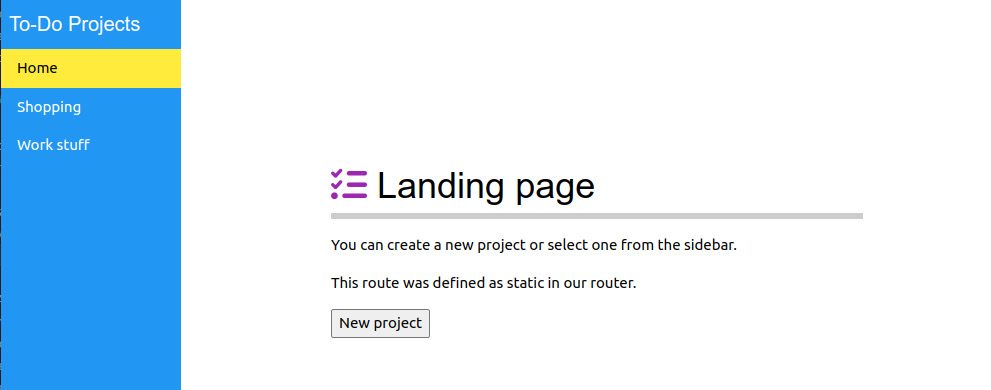
Рисунок 5.1 - Наша лэндинг страница
Как видно на Рисунке 5.1, целевая страница является также местом, где мы можем создавать новые проекты. Для сбора пользовательского ввода мы, как и раньше, используем модальные диалоги.
На боковой панели отображается ссылка на страницу Home (целевая страница) и список с названиями различных проектов, которые мы создали. При щелчке на каждом из них маршрут в браузере (URL) будет обновляться, как и страница, и мы увидим нечто подобное этому:
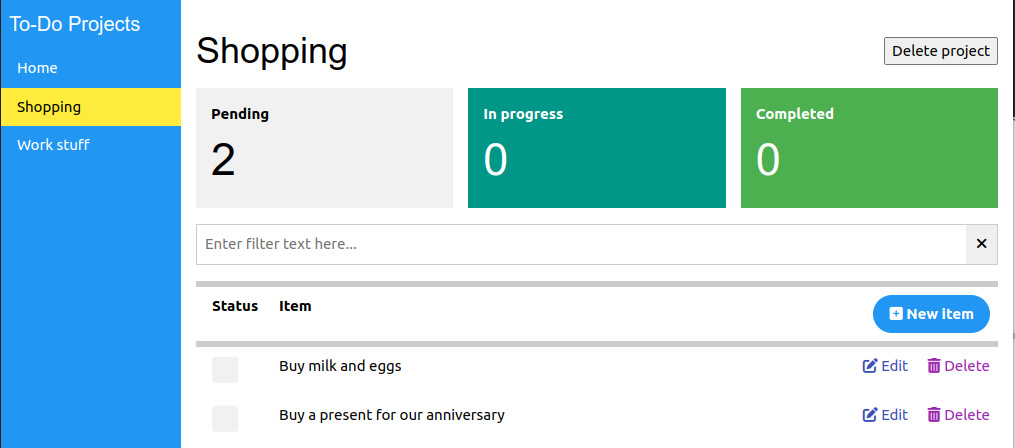
Рисунок 5.2 - Страница проекта To-Do
Последний скриншот вы можете узнать, поскольку именно его отображает наш компонент ToDoProject.vue. Собственно говоря, для достижения этого результата потребуется совсем немного модификаций. А пока давайте начнем с маршрутов.
Определение маршрутов и объект Router
Чтобы создать маршруты для нашего проекта, необходимо сначала определить их в собственном модуле. В каталоге /router создайте файл index.js со следующим содержимым:
/src/router/index.js
import {createRouter,createWebHashHistory} from 'vue-router' //1
import Landing from "../views/Landing.vue" //2
const routes = [
{path: "/",name: "landing", component: Landing},
{path: "/project/:id",name: "project",
component: () =>
import("../views/ToDoProject.vue"), //3
props: true
}],
router = createRouter({ //4
history: createWebHashHistory(), //5
routes,
scrollBehavior(to, from, savedPosition){return{top:0}}
})
export default router;Начнем наш файл с импорта двух конструкторов из пакета vue-router, в строке //1:
- createRouter, который создаст объект router, который мы можем внедрить в наше приложение в качестве плагина
- createWebHashHistory, который является конструктором, который мы передадим нашему объекту router, и указывает, как он будет управлять перезаписью URL в браузере
Web hash history будет отображать # (знак "решетки") в URL и указывать, что вся навигация указывает на один файл. Все навигационные и URL-параметры будут следовать этому знаку. Это самый простой метод, не требующий специальной настройки. Однако есть и другие доступные методы: Web history (также известный как HTML5 mode или pretty URLs) и Memory.
Web history не использует хэш-нотацию, но требует специальной конфигурации сервера. Как это сделать, мы рассмотрим на примерах в главе 10, Развертывание приложения. Режим Memory не изменяет URL и используется в основном для веб-представлений (как в гибридных фреймворках, таких как NW.js, Electron, Tauri, Cordova, Capacitor и т.д.) и серверного рендеринга SSR). Пока мы остановимся на методе Web hash history.
В строке //2 мы импортируем компонент, используя нотацию static, и определяем массив routes с нашими маршрутами. Каждый маршрут представлен объектом, содержащим как минимум следующие поля:
- path: Строка, представляющая URL, связанный с компонентом
- name: Строка, которая ведет себя как уникальный идентификатор маршрута и которую мы можем вызывать программно
- component: Компонент, который будет отрисовываться
Обратите внимание, что в строке //2 мы импортируем статический компонент, а в строке //3 используем нотацию динамического импорта. Это означает, что первый маршрут (с именем "landing") будет включен в основной пакет, а второй маршрут (в строке //3 с именем "project") будет загружен только при первой необходимости, из отдельного пакета.
Используя маршруты, мы можем создать стратегию, позволяющую улучшить загрузку приложения и уменьшить размер пакета.
И наконец, в строке //4 мы создаем наш объект router, используя конструктор и передавая объект options. Обратите внимание на то, что в строке //5 мы передаем поле history конструктору для выбранного нами метода history.
Мы также передаем наши маршруты (очевидно), а также в качестве примера создаем одну из возможных навигационных защит (navigation guards), чтобы убедиться, что после перехода по каждому маршруту окно прокручивается до самого верха. Без этого мы можем столкнуться со странным побочным эффектом, когда прокрутка не будет меняться между "страницами".
Navigation guards срабатывают до и после навигационного события. Они могут использоваться во множестве ситуаций, например, для контроля аутентификации или предварительной загрузки данных. Полный список guards с примерами приведен в официальной документации.
Во втором маршруте мы также включили в обозначение пути вариант с включением именованного параметра, перед которым ставится двоеточие (:id). Этот маршрут будет соответствовать всему, что следует за /project/, и присваивать его реактивной переменной, к которой мы можем обращаться программно (как это работает, мы увидим позже).
Маршрут также имеет дополнительное поле, props: true. Оно указывает на то, что параметр, названный в маршруте, будет автоматически передан компоненту в качестве пропса, если компонент определил пропс с таким же именем. Это станет полезным и очевидным в следующих разделах.
После того как маршруты и маршрутизатор определены, пришло время импортировать их в файл main.js и подключить к нашему приложению. Теперь файл будет выглядеть следующим образом:
/src/main.js
import { createApp } from 'vue'
import router from "./router"
import App from './App.vue'
import Modals from "./plugins/modals"
import styles from "./assets/styles.css"
createApp(App).use(router).use(Modals).mount('#app')Достаточно просто. Теперь необходимо создать компоненты, которых сейчас нет, и адаптировать те, которые есть. Прежде чем приступить к работе с кодом, давайте посмотрим, какие новые компоненты маршрутизатор предоставляет нашему приложению.
Шаблонные компоненты маршрутизатора
Когда мы включаем роутер в приложение, он инжектирует в глобальную область видимости следующие новые компоненты:
- RouterView: Этот компонент предоставляет место, где будут отображаться компоненты маршрута.
- RouterLink: Обеспечивает простой способ привязки к маршрутам; с помощью удобных пропсов и стилей мы можем контролировать внешний вид и конечный элемент рендеринга.
Вместе с определением роутера и маршрутов эти два компонента в нашем шаблоне позволяют предложить навигацию и лучше организовать наш код. Прежде чем разбираться с ними, давайте посмотрим, как они работают в нашем приложении. Начнем модифицировать наш компонент App.vue, чтобы превратить его в контейнер макета (стили опущены):
App.vue
<script setup>
import Sidebar from './components/Sidebar/Sidebar.vue';
</script>
<template>
<div class="app">
<Sidebar></Sidebar>
<main>
<router-view></router-view>
</main>
</div>
</template>Как видите, мы включаем новый компонент Sidebar, который будет содержать основную навигацию нашего приложения. Затем мы помещаем единственный компонент <router-view>, в котором наш маршрутизатор будет отображать каждую страницу. Что касается стилей, то за подробностями я отсылаю к коду на GitHub.
Теперь пришло время создать компонент Sidebar по пути /src/components/Sidebar/Sidebar.vue и скопировать код из репозитория. В этом небольшом файле есть на что посмотреть. Начнем разбираться с шаблона и с того, как мы используем экземпляры RouterLink. Первый из них статичен и указывает на целевую страницу. Вместо того чтобы просто использовать ссылку или тег <a>, мы определяем цель ссылки как объект, в котором напрямую ссылаемся на имя маршрута:
<RouterLink :to="{name:'landing'}" class="w3-padding" active-class="w3-yellow">Home</RouterLink>По умолчанию при выводе этого компонента он становится тегом <a>, а атрибут href динамически преобразуется в соответствующий маршрут. Если мы изменим определение маршрута и зададим ему другой путь, это никак не повлияет на данный код.
Хорошей практикой является обращение к маршрутам по их именам, а не по их URL. В случае, если нам необходимо передать в URL параметры строки запроса, мы можем легко сделать это, передав в качестве атрибута params объект с парами ключ/значение. Вот пример:
<RouterLink :to="{name:'search',params:{text:'abc'}}">Search</RouterLink>Предшествующий атрибут params будет отображен как URI со строкой запроса ?text=abc.
Как мы уже говорили, если у маршрута активен атрибут props и принимающий компонент определил одноименный prop, то значение будет присвоено автоматически. Именно такая ситуация позволяет нам сформировать список ссылок и передать на страницу нашего проекта идентификатор каждого проекта, что можно увидеть далее в файле:
<div v-for="p in _projects" :key="p.id">
<RouterLink :to="{name:'project',params:{id:p.id}}">
{{p.name}}
</RouterLink>
</div>При создании проекта на лэндинг странице каждому из них автоматически присваивается уникальный идентификатор, который мы используем в предыдущем коде. Как и в случае с другими пропсами, мы можем следить за изменениями и реагировать на них, загружая соответствующие пункты To-Do для каждого проекта.
Исходя из этого, мы модифицировали файл ToDoProject.vue, чтобы определить пропс (тип определять не нужно):
$props = defineProps(["id"])Также мы установливаем watch для обнаружения изменений с помощью этих строк в script разделе:
import { watch } from "vue"
watch(() => $props.id, loadProject)Этот watch получает функцию, которая возвращает атрибут prop, а затем запускает функцию loadProject(). На этом этапе вы можете спросить, зачем нам это нужно, ведь каждый URL-адрес отличается. Ответ заключается в том, что Vue и router загружают компонент только в первый раз, когда он нужен. До тех пор, пока он остается в поле зрения, он не перезагружается и только обновляет реактивные свойства. Поскольку наш код script setup выполняется только при первой загрузке, в момент создания, нам нужен способ обнаружения изменений для выполнения нереактивных операций, таких как загрузка пунктов To-Do для проекта из localStorage.
Остальные изменения можно посмотреть в репозитории. В компонентах, работающих со списком дел, меняется очень мало, в этом и заключается смысл инкапсуляции. Даже модификация ToDoProject.vue невелика.
Однако есть одно дизайнерское решение, на которое следует обратить внимание: использование модели pub/sub для синхронизации меню боковой панели.
Мы создали синглтон с шиной событий (eventBus). Когда мы создаем новый проект или удаляем его, мы вызываем событие обновления с помощью следующей строки:
eventBus.emit("#UpdateProjects")Мы регистрируем прослушивание событий в тех компонентах, которым это необходимо, во время события монтирования жизненного цикла компонента, и снимаем его с регистрации перед размонтированием. В нашем случае он нужен только в компоненте Sidebar, но при необходимости его можно разместить в любом месте нашего приложения:
onMounted(() => {
eventBus.on("#UpdateProjects", updateProjects)
})
onBeforeUnmount(() => {
eventBus.off("#UpdateProjects", updateProjects)
})Имя события тривиально и не подчиняется никаким соглашениям. В этой книге мы добавляем к нему "решетку", как личное предпочтение.
В предыдущих реализациях, а также в компоненте ToDoProject.vue, мы использовали родителя в качестве канала для обмена информацией между компонентами-братьями, о чем мы говорили ранее. Здесь мы используем другую модель, паттерн pub/sub, чтобы не загрязнять компонент App.vue подобной задачей.
В главе 7, Управление потоком данных, мы рассмотрим другие подходы к централизованному управлению состоянием. Теперь рассмотрим более подробные примеры и детали использования маршрутизатора в более продвинутых сценариях.
Вложенные маршруты, именованные представления и программная навигация
До сих пор мы создавали статические и динамические маршруты, даже с некоторыми параметрами в адресе. Но маршрутизатор может делать даже больше. Используя именованные маршруты, мы можем также создавать "подмаршруты" и именованные "sub-view" для создания более глубоких навигационных деревьев и сложных макетов.
Начнем с примера. Предположим, у нас есть трехуровневая структура данных, и мы хотим реактивно представить ее пользователю таким образом, чтобы он мог выбрать один уровень, а затем "спуститься" к деталям. Мы также хотим, чтобы это отражалось в URL-адресе, чтобы можно было поделиться или сослаться на полный текст дела. В данном случае уровнями будут страна, штат и город. В этом случае пользовательский интерфейс будет выглядеть следующим образом:
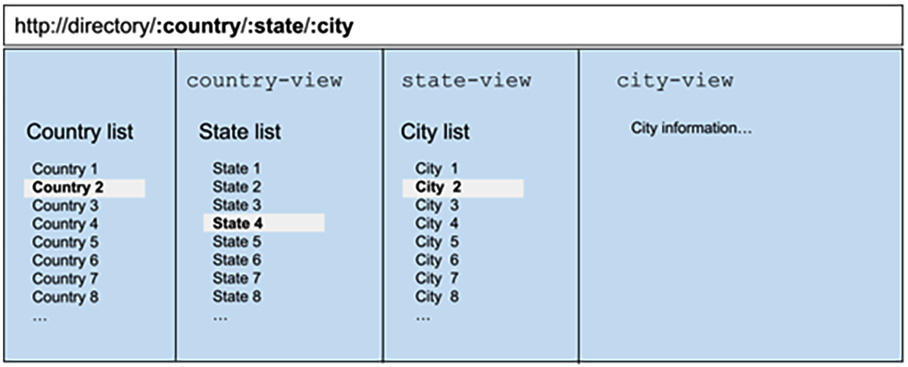
Рисунок 5.3 - Выборка с использованием нескольких именованных представлений (view) и подмаршрутов
Как видно из скриншота, при выборе пользователем страны заполняется список штатов и обновляется URL. При выборе штата обновляется список городов, и, наконец, при выборе города информация появляется в последнем столбце.
Возможно, вы уже встречали такой способ навигации. Существует множество способов его реализации, одни из которых более эффективны, чем другие. Мы хотим реализовать это в качестве учебного упражнения, поэтому начнем с определения маршрутов. Вот фрагмент массива определения наших маршрутов:
{
path: "/directory", name: "directory",
component: () => import("../views/Directory.vue"),
children: [
{
path: ":country", name: "states", props: true,
component: () => import("../views/State.vue"),
children:[
{
path:":state", name: "cities", props: true,
component: () => import("../views/City.vue")
}
]
}
]
}Определение вложенных маршрутов
На первый взгляд, мало что изменилось, кроме включения в маршрут нового атрибута: children[]. Этот атрибут получает массив маршрутов, которые, в свою очередь, могут иметь другие дочерние маршруты, как мы видим в предыдущем фрагменте кода.
Дочерние маршруты будут отображаться в компоненте RouteView своих родителей, а их пути будут конкатенированы с путями родителей, если только они не начинаются с корня (с обратной косой черты).
Для навигации по маршруту, который будет отображаться в родительском компоненте RouteView, необходимо использовать атрибут RouteView.
Для перехода к каждому маршруту мы можем использовать любой из методов, распознаваемых маршрутизатором. Однако хорошей практикой является использование их имен и передача любого параметра или строки запроса через объект, и пусть маршрутизатор разрешает URL.
В качестве примера посмотрим, как в компоненте Directory.vue мы используем элемент RouterLink:
/src/views/Directory.vue component, lines 13-18
<div v-for="c in countries" :key="c.code">
<RouterLink
:to="{name:'states', params:{country:c.code}}"
active-class="selected">
{{c.name}}
</RouterLink>
</div>Мы включили наш компонент RouterLink внутрь цикла, чтобы создать столько ссылок, сколько необходимо на основе наших данных. Целью ссылки является объект, в который мы передаем имя маршрута (states), а также передаем параметры, соответствующие определению маршрута и пропса компонента.
Обратите внимание, что путь компонента определен как параметр (он начинается с двоеточия - :country), и он также соответствует props-определению объекта в State.vue. Именно это соответствие позволяет маршрутизатору автоматически передавать нам данные.
Проанализировав код, можно заметить, что в самом маленьком дочернем компоненте, файле City.vue, мы определяем в реквизите и страну, и государство. Однако в определении маршрута появляется только один параметр - state (:state).
Тем не менее, запустив пример, можно заметить, что этот пропс также заполнен. Это происходит потому, что дочерние компоненты наследуют вместе с URL-путем все параметры, определенные в маршруте родительского компонента. В данном случае наш компонент также получает параметр :country, который был передан родителю, даже если он не отображается в его конкретном маршруте.
Запустив приложение, вы увидите нечто похожее на этот снимок экрана:
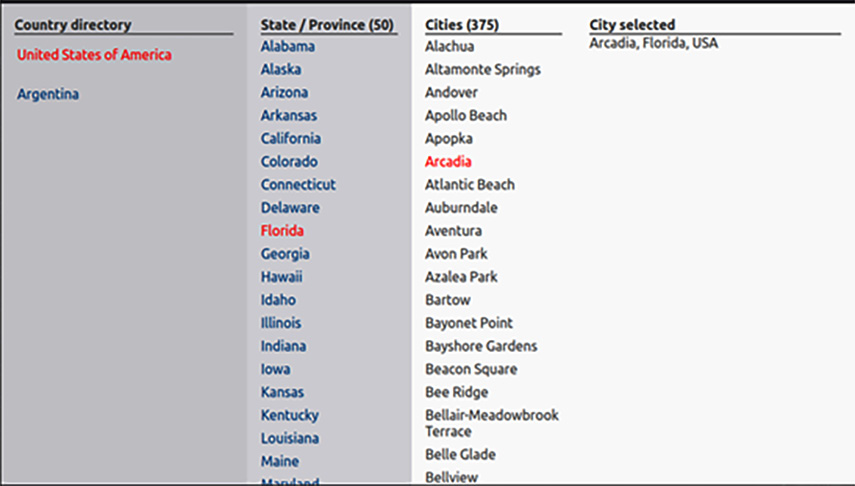
Рисунок 5.4 - Пример вложенных маршрутов, с выделениями.
Для простоты из статических файлов были включены только две страны. В реальном проекте эти данные будут получены из базы данных.
До сих пор мы использовали компоненты RouteView "по умолчанию", но маршрутизатор Vue позволяет включать несколько представлений в один компонент, присваивая им разные имена. Здесь мы рассмотрим только обозначения, поскольку реализация тривиальна. Рассмотрим компонент со следующим шаблоном:
<div>
<RouterView name="header"></RouterView>
<RouterView name="sidebar"></RouterView>
<RouterView></RouterView>
</div>В предыдущем коде мы присваиваем нашим маршрутам идентификацию с помощью атрибута name. У нас также есть представление (view) без имени, в этом случае оно считается представлением "по умолчанию", или с именем default.
Для использования этой новой схемы немного меняется определение маршрутов. Теперь в каждом определении у нас нет атрибута component, а вместо него есть атрибут components (во множественном числе), который ожидает объект. Имя каждого поля в объекте должно совпадать с именами, заданными нашим компонентам RouterView, и быть равным объекту.
Для предыдущего фрагмента кода эквивалентное определение маршрута будет выглядеть следующим образом:
{
path: "/layout",
name: "main",
components:{
default: () => import('...'),.
header: () => import('...'), .
sidebar: () => import('...').
}}Используя этот тип определения, мы можем создавать сложные макеты, поскольку можем также определить подмаршруты, которые будут использовать, например, заголовок и боковую панель из родительского блока и будут отображаться только в представлении по умолчанию. У нас есть впечатляющее количество возможностей для создания динамических пользовательских интерфейсов.
Одна из важных тем, которую мы должны затронуть, прежде чем перейти к следующему разделу, - это программная навигация. До сих пор мы использовали новые компоненты, предоставляемые маршрутизатором, но мы также можем запускать навигацию непосредственно из нашего JavaScript, не полагаясь на то, что пользователь вызовет событие.
Для этого Vue Router предоставляет нам два удобных конструктора, которые можно использовать в сценариях наших компонентов: useRoute и useRouter. Мы импортируем эти конструкторы в наши компоненты с помощью следующего кода:
import { useRoute, useRouter } from "vue-router"
const $route = useRoute(),
$router = useRouter()Как вы понимаете, $route предоставляет нам информацию о текущем маршруте, а $router позволяет изменять и запускать навигационные события.
Объект $router предоставляет несколько методов, наиболее часто используемые из которых перечислены ниже:
.push()
Самый важный метод. Он проталкивает новый URL в веб-историю и осуществляет переход к соответствующему компоненту.
Это программный эквивалент использования RouterLink. Он принимает либо строку с URL для перехода, либо объект с необязательными атрибутами. Ниже приведены примеры для каждого принимаемого параметра:
// Navigate to a URL
$router.push("/my/route")
// Navigate to a URL, using an object
$router.push({path: "/my/route"})
// Navigate to a route, with parameters
$router.push({
name:"route-name",
params:{key:value}
})
// Navigate to a route, with query strings
$router.push({
name:"route-name",
query:{key:value}
}).replace()
Заменяет текущий компонент навигации, не изменяя URL. Принимает те же параметры, что и .push
.go()
Этот метод получает в качестве параметра целое число и запускает навигацию по истории браузера. Положительные числа ведут вперед, а отрицательные - назад по истории навигации.
Чаще всего он используется для реализации ссылки "назад" в приложении. Вот несколько примеров:
// Go back one entry
$router.go(-1)
// Go forward one entry
$router.go(1)Как уже говорилось, это наиболее часто используемые методы, которые необходимо иметь в наличии. Могу сказать, что их использование позволяет решить подавляющее большинство регулярных задач.
Полный список доступных методов можно найти в официальной документации, они позволяют справиться и с возникающими крайними случаями. Рекомендую ознакомиться с ними, хотя бы для того, чтобы знать о них, по адресу https://router.vuejs.org/api/interfaces/Router.html#properties.
К таким случаям можно отнести: динамическое добавление и удаление маршрутов (.addRoute() и .removeRoute()), получение зарегистрированных маршрутов (.getRoutes()), проверка наличия маршрута перед переходом к нему (.hasRoute()) и т.д. Мы не будем их использовать, поэтому подробно рассматривать их здесь нецелесообразно.
Напротив, объект $route предоставляет нам информацию о текущем пути (URL), по которому происходит рендеринг нашего компонента. Как и в предыдущем примере, здесь приведен список наиболее часто используемых атрибутов и их назначение:
| Атрибуты | Описание |
| .name | Возвращает текущее имя маршрута. |
| .params | Возвращает объект с параметрами, указанными в пути (URL). Если они были сопоставлены с пропсами, то значения могут пересекаться. |
| .query | Возвращает объект с декодированной строкой запроса, привязанной к текущему пути. |
| .hash | Если таковые имеются, то возвращается путь в URL, следующий за знаком хэша (# ). |
| .fullPath | Возвращает строку с полным путем маршрута. |
В примерах этой книги мы неоднократно будем использовать .name(), .params() и .query(), поскольку они, как правило, являются наиболее часто используемыми. Полный список методов и свойств можно найти в официальной документации.
Важные различия в обозначениях
Мы использовали конструкторы useRoute и useRouter в Composition API с нотацией script setup. В Options API нет необходимости инициализировать эти объекты. Оба они доступны автоматически через this.$route и this.$router. Также объекты $route и $router автоматически доступны в шаблоне при использовании Composition API.
Полный пример кода можно найти в репозитории GitHub, в разделе Глава 5/Вложенные маршруты, по этому адресу.
Теперь, когда мы знаем, как работать с маршрутами, параметрами и строками запросов, пришло время рассмотреть некоторые общие шаблоны аутентификации в SPA, поскольку для многих из них необходимы различные пути (URL).
Исследование шаблонов аутентификации
Сила SPA становится очевидной, когда за ними стоит сервер, предоставляющий дополнительные сервисы. Одним из таких сервисов является аутентификация. В большинстве приложений возникает необходимость идентификации пользователей и предоставления дополнительных услуг на основе их прав, статуса, конфиденциальности, группы или любой другой категории, относящейся к контексту приложения. Ярким примером этого являются приложения веб-почты, такие как Outlook или Gmail.
Современные веб-стандарты предоставляют нам несколько возможностей для осуществления асинхронного взаимодействия с сервером. Их часто называют AJAX (AJAX расшифровывается как Asynchronous JavaScript and XML).
В самом базовом виде для таких сетевых взаимодействий мы могли бы использовать объект XMLHttpRequest, но новые спецификации предоставляют нам прямую функцию fetch(), которая является более удобной и стандартной для браузеров.
Хотя эти методы вполне допустимы, для других целей, кроме простых нужд, лучше использовать библиотеку, предоставляющую более широкие функциональные возможности, построенные поверх этих технологий - например, такую, которая предоставляет API для соответствия методам HTTP-запросов (GET, POST, PUT, OPTIONS и DELETE) для удобного использования RESTful API (где REST означает Representational State Transfer, тип архитектуры, используемый в сетевых коммуникациях).
Подробнее об этом мы поговорим в главе 8, Многопоточность с Web Workers. Пока же просто имейте в виду, что лучшим вариантом будет библиотека для обработки сетевых асинхронных взаимодействий. В нашем случае мы будем использовать замечательную библиотеку Axios, которую можно установить в свое приложение с помощью следующей команды:
$ npm install axiosЗатем в своем сервисе или компоненте вы можете импортировать и использовать библиотеку с помощью следующего кода:
import axios from "axios"Библиотека предоставляет методы, соответствующие каждому HTTP-запросу (.get(), .post(), .put() и т.д.), каждый из которых возвращает промис, разрешающийся в результат запроса или отклоняющий его в случае ошибки.
После этого мы готовы рассмотреть некоторые общие шаблоны для аутентификации пользователей в наших приложениях.
Простая аутентификация по имени пользователя и паролю
Это самый простой подход к аутентификации пользователей, при котором проверка учетных данных выполняется нашей реализацией на сервере. В этом случае серверный бэкенд предоставляет API для проверки набора учетных данных, собранных нашим SPA.
Традиционно учетные данные хранятся на сервере, в базе данных, а обмен данными будет осуществляться поверх Secure Sockets Layer (SSL) или шифрованного обмена, что одно и то же. Рассмотрим процесс работы графически:
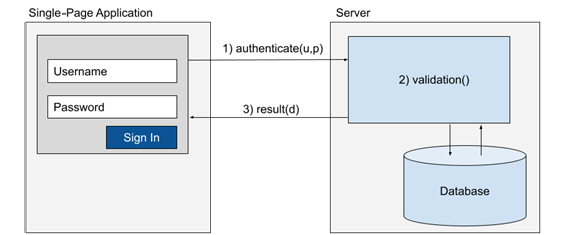
Рисунок 5.5 - Простая аутентификация по имени пользователя и паролю
В этом рабочем процессе происходит следующее:
- SPA собирает значения имени пользователя и пароля и передает их в определенную конечную точку (endpoint) нашего сервера для аутентификации.
- Сервер использует информацию, хранящуюся в базе данных, для проверки имени пользователя и пароля.
- Результат операции возвращается клиенту SPA в ответ на его первоначальный запрос (1).
Хотя на рисунке 5.5 показано количество шагов, следует учитывать, что все это делается всего за один сетевой вызов и его ответ. Разработка кода проверки на сервере выходит за рамки данной книги, но код внутри нашего сервиса или компонента Vue 3 будет выглядеть примерно так:
import axios from "axios"
import { ref } from "vue"
const _username = ref(""), _password = ref("")
function doSignIn() {
axios.post("https://my_server_API_URL",
{username:_username.value,password:_password.value})
.then(response=>{
console.log(response.status)
console.log(response.data)
}).catch(err=>{...})
}Как видите, реализация достаточно проста и зависит от нашей собственной логики и дизайна API сервера. Важно помнить, что необходимо проверять статус ответа (все, что находится между 200 и 299, является успехом) и данные, отправленные сервером, чтобы действовать соответствующим образом. Все коммуникации и преобразование данных за нас выполняет Axios (при условии, что наш API принимает и обрабатывает данные в формате JSON).
В случае успеха мы должны сохранить результат в состоянии нашего приложения и соответственно разрешить доступ пользователю, в основном разблокировав навигацию по закрытым или ограниченным маршрутам. Такая защита может быть реализована множеством различных способов, наиболее распространенными из которых являются использование навигационных защит (guards), создание динамических маршрутов и т.д.
Этот способ вполне допустим и широко применяется в большинстве приложений. Однако он имеет ряд недостатков:
- Мы отвечаем за ведение базы данных с именами пользователей и паролями (пожалуйста, в зашифрованном виде!) и реализацию логики проверки
- Мы несем юридическую ответственность за обработку данных пользователей в соответствии с местным законодательством
- Мы отвечаем за всю безопасность системы, от начала до конца
- Пользователь должен помнить или нести ответственность за свои учетные данные
- Мы должны предусмотреть способы обработки нестандартных ситуаций, а также проблем пользователей и поиска учетных данных
Эти недостатки ни в коем случае не являются сдерживающим фактором, но являются важными моментами, которые следует иметь в виду, если мы пойдем этим путем. Так или иначе, большинство приложений должны иметь способ аутентификации пользователей, который зависит от их собственной логики и реализации, поскольку не все наши пользователи (в зависимости от контекста) будут готовы использовать другую форму аутентификации, как мы увидим далее.
OpenID и сторонняя аутентификация
Помимо вопросов безопасности, основной проблемой при аутентификации является то, как легко эти учетные данные могут быть утеряны или неправильно использованы конечным пользователем. Это случается с каждым из нас. Чем больше сервисов мы используем в Интернете, тем большее количество учетных данных пользователю необходимо "помнить".
Существует множество различных методов решения этой проблемы, позволяющих снизить нагрузку на пользователя, связанную с запоминанием всех этих имен и паролей. Одним из таких стандартов является протокол OpenID.
Протокол OpenID обеспечивает аутентификацию пользователей без необходимости обмена учетными данными (именами пользователей и паролями) между сайтами. Он основан на работе протокола OAuth 2.0, который используется для безопасного обмена информацией и ресурсами без необходимости использования паролей.
Это достигается путем обмена токенами между различными участниками процесса. Стандартом для таких коммуникаций является использование JSON Web Tokens (JWTs). Давайте рассмотрим каждый из этих терминов немного подробнее, чтобы лучше понять, как работает этот протокол.
JWT - это строка, содержащая три секции, разделенные точкой (.) и закодированные в Base64. Затем каждая секция кодирует JSON-объект со следующей информацией:
- Header: содержит криптографическую информацию, используемую для кодирования токена, такую как алгоритм, тип токена (обычно JWT), а в некоторых случаях даже тип данных, представленных в полезной нагрузке.
- Payload: этот объект содержит информацию, которую мы хотим (должны) передать, и в основном имеет "свободный формат", то есть может содержать любую пару key:value по мере необходимости. Однако есть несколько четко определенных полей, которые также могут быть использованы, например "iat" (Issued At Time), в котором содержится временная метка создания токена. Самое главное, этот объект должен содержать уникальный идентификатор пользователя (поле "sub", для субъекта).
- Signature: Подпись представляет собой строку, образованную путем конкатенации зашифрованных строковых представлений заголовка и полезной нагрузки, выраженных в Base64. Для шифрования используется секретный ключ (пароль), известный только аутентифицирующему серверу и серверу сайта.
Получив токен, сайт в рабочем процессе декодирует и проверяет его с помощью секретного ключа, используя тот же метод, что и эмитент. Если подписи не совпадают, то считается, что токен испорчен или скомпрометирован, и он отклоняется. JWT может быть перехвачен и декодирован третьей стороной, поэтому этот метод действует как дополнительное средство защиты от подделки. Рассмотрим пример создания токена:
- Header: {"alg": "HS256", "typ": "JWT"}. Здесь мы используем алгоритм HS256 и объявляем используемый тип как JWT.
- Payload: {"sub":"1234567890","name":"Pablo D. Garaguso", "iat": 1516239022}.
- Secret encryption key: секретный ключ.
Поле подписи создается по такой формуле (при условии, что у нас есть функция, шифрующая текст по алгоритму HS256):
HMACSHA256(base64UrlEncode(header) + "." + base64UrlEncode(payload), "secret key")
И наконец, полученные строки в кодировке Base64 снова конкатенируются, в результате чего мы получаем вполне работоспособный токен. Также обратите внимание на то, что каждая секция (Header, Payload и Signature) разделяется точкой (.):
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IlBhYmxvIEQuIEdhcmFndXNvIiwiaWF0IjoxNTE2MjM5MDIyfQ.mPr551xpsCgmIzp8EZuSCoy7t7iQNpp_iGzIR14E_Jo
Для проверки этого токена можно воспользоваться таким сервисом, как https://jwt-decoder.com/. Однако для его проверки необходимо использовать секретный ключ. Проверить его можно на сайте https://jwt.io, где также можно найти дополнительную информацию об этом стандарте.
В протоколе OpenID JWT используются для передачи и проверки информации между сторонами, поэтому так важно хорошо понимать эту концепцию. Существует несколько рабочих процессов, поддерживаемых протоколом. Давайте рассмотрим упрощенное представление потока кода авторизации (https://openid.net/specs/openid-connect-core-1_0.html) протокола со всеми участниками, а затем посмотрим, какие части нам нужно реализовать в наших Vue 3 SPA:
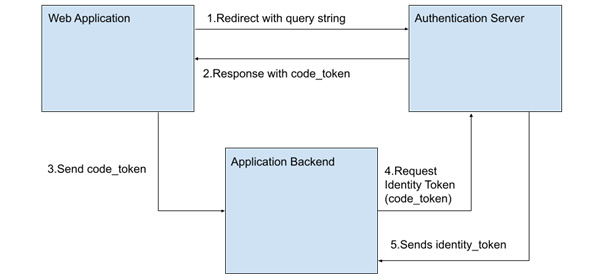
Рисунок 5.6 - Поток кода авторизации OpenID во всей его красе.
Как видите, для реализации этого рабочего процесса нам необходимы три участника: 1) наш SPA, обрабатывающий множество маршрутов, 2) сервер аутентификации service provider (SP) и 3) наш собственный backend-сервер. Можно выполнить аутентификацию и проверку без бэкенда, в браузере, тогда потребуется только два участника, но это не рекомендуется, так как раскрывается секретный ключ в нашем JavaScript.
Однако такая возможность существует для встроенных приложений, например мобильных, где пользователь не имеет свободного доступа к коду страницы (в гибридных приложениях).
Для реализации рабочего процесса клиент (наше приложение) должен зарегистрироваться в службе аутентификации. Процесс зависит от каждой сущности, но в результате у нас будет зарегистрировано следующее:
- Идентификационная строка client_id, уникальная для нашего приложения.
- Значение secret_key, которое будет известно только серверу аутентификации и нашему внутреннему приложению. Оно будет использоваться для кодирования и подписи наших токенов.
- Серия конечных точек (endpoints) в сервере аутентификации и в нашем приложении, куда будет перенаправляться пользователь на каждом шаге. Соответствующий обмен токенами будет осуществляться при этих перенаправлениях как часть строки запроса в URL.
Итак, давайте рассмотрим эти шаги в деталях, а также то, как их реализовать в нашем приложении на Vue 3:
1.
Пользователю необходимо пройти аутентификацию, поэтому мы перенаправляем его на конечную точку, указанную нам сервером аутентификации. Строка запроса должна содержать следующие (обязательные) поля:
- scope: openid
- response_type: код
- client_id: Идентификатор клиента, выданный сервером аутентификации
- redirect_uri: Тот самый адрес, который мы зарегистрировали на сервере, куда будет перенаправлен пользователь после успешной аутентификации
- state: Любые данные или состояние приложения, которые мы хотим получить в ответ после аутентификации
Для подготовки URL перенаправления мы сначала создаем объект с указанными выше полями и значениями, а также используем URLSearchParams для создания строки запроса (см. https://developer.mozilla.org/en-US/docs/Web/API/URLSearchParams):
const query_data = {scope: "openid", ...},
query_string = new URLSearchParams(query_data).toString()Следующим шагом мы можем использовать объект location для выполнения перенаправления:
location.assign("https://auth_endpoint" + "?" + query_string)2.
При успешной аутентификации сервер аутентификации перенаправит пользователя на конечную точку, которую мы зарегистрировали в качестве получателя. Передаваемые параметры запроса будут зависеть от результата операции:
- Успешный вход в систему:
- code: code_token, который в дальнейшем необходимо обменять на identity_token.
- state: Любые данные, которые мы отправили на сервер и хотим получить обратно. Мы можем использовать это для перенаправления пользователя внутри нашего приложения, например.
- Неудачный вход в систему:
- error: Код ошибки, определенный протоколом (interaction_required, invalid_request_uri, и так далее).
Переадресация вызовет загрузку нашего приложения, и маршрутизатор отрендерит указанный нами компонент. В настройках нашего скрипта нам необходимо перехватить переданную нам строку запроса, чтобы затем использовать ее в следующем шаге. Сделать это без использования сторонних библиотек можно с помощью следующего кода:
import { useRoute } from "vue-router"
const $route = useRoute()
if ($route.query.error){
// Аутентификация не удалась, примите меры
} else {
// Аутентификация прошла успешно, сделайте что-нибудь
sendToServer($route.query.code)
}3.
На этом шаге мы просто отправляем полученный код на бэкенд, что означает реализацию функции sendToServer(), о которой говорилось ранее. Поскольку теперь мы имеем дело с нашей собственной реализацией, способ сделать это тривиален. В данном примере мы используем Axios:
import{ axios }from "axios"
function sendToServer(code) {
axios
.post("URL нашего сервера", {код})
.then(result=>{
// Устанавливаем токен в наши заголовки
axios.defaults.headers.common = {
"Authorization": "Bearer " + result.data.identity_token
}
}).catch(()=>{
// Обработка ошибки
})
}В предыдущем примере мы отправили на сервер строку code_token и получили от него в качестве ответа строку identity_token*. Затем мы делаем еще один шаг вперед и устанавливаем в заголовках по умолчанию для нашего приложения стандартный заголовок Authorization с маркером Bearer. С этого момента нашему серверу достаточно проверить заголовки и убедиться, что запрашиваемая операция принадлежит действительному пользователю.
Выполнение проверки токенов и шагов 4 и 5 выходит за рамки данной книги, поскольку мы рассматриваем приложения на Vue 3. Как видите, та часть, которую должен обрабатывать наш SPA, довольно проста и не содержит большого количества кода (некоторые проверки ошибок для краткости были опущены).
Существует достаточно большое количество приложений, в которых используются токены.
Существует большое количество синдицированных сервисов аутентификации, как бесплатных, так и платных, которые мы можем реализовать в нашем приложении. Наиболее распространенными в наши дни являются значки, перенаправляющие пользователей на их использование, например, для входа в систему с помощью Google, Facebook, Twitter, GitHub, Microsoft и т.д.
Существуют также метасервисы, предоставляющие всех вышеперечисленных провайдеров внутри хорошо упакованных библиотек, например Auth0 (сейчас входит в состав Okta). Когда дело доходит до реализации этого рабочего процесса, мы, конечно, не испытываем недостатка в вариантах.
Беспарольная аутентификация или аутентификация по одноразовому паролю (OTP)
Другим решением, позволяющим отказаться от использования учетных данных, является беспарольный доступ. Основная идея заключается в том, чтобы полагаться на безопасность другой системы (электронная почта, мобильные тексты, приложения-аутентификаторы и т.д.) для подтверждения пользователя.
В процессе генерируется чувствительный к времени код "одноразового использования" и отправляется пользователю через систему поддержки через внутренний сервис. Внешний сервис (приложение) ожидает ввода права пользователем в определенный промежуток времени.
Например, распространенной реализацией является отправка бэкендом на телефон пользователя текстового сообщения с кодом, который необходимо ввести в приложении до истечения времени.
Здесь представлено визуальное представление этого рабочего процесса, учитывая, что пользователь был зарегистрирован с помощью электронной почты или номера телефона. Предполагается, что они известны, а значит, их принадлежность проверена:
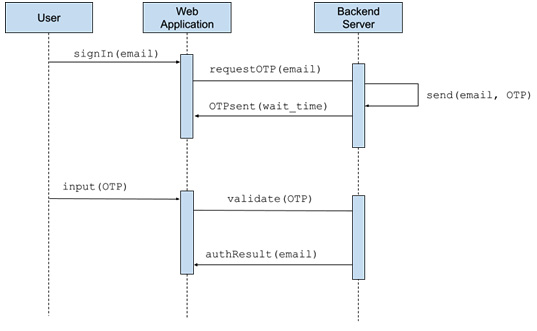
Рисунок 5.7 - Беспарольная аутентификация на основе электронной почты
В предыдущем сценарии работы обратите внимание, что код OTP не попадает в веб-приложение до тех пор, пока пользователь не введет его. Валидация происходит в бэкенде, а не во фронтенде. Это делает наше приложение очень простым, поскольку ему нужно только сначала собрать письмо и отправить его на сервер, а затем в течение заданного времени ждать нового ввода. В сервисе или компоненте, использующем Axios, этот код будет выглядеть примерно так:
const _user_email=ref(""),
_wait_seconds=ref(0),
_show_input_code=ref(false),
_otp_code=ref("")
function signInUser(){
axios.post("https://requestOTP_url",
{email:_user_email.value})
.then(result=>{
_wait_seconds.value=result.data.wait_time;
_show_input_code.value=true;
startOTPtimer();
}).catch(err=>{...})
}
function startOTPtimer(){
let interval_id=setInterval(()=>{
if(_wait_seconds.value>0){_wait_seconds.value--;}
else {clearInterval(interval_id);}},1000)
}
function checkOTP(){
axios.post("https://validateOTP_URL",{code:_otp_code.value})
.then(result=>{
if(result.status>200 && result.status<300){
// Пользователь подтвержден, переходим к защищенному маршруту
}else{
// Валидация не прошла. Перенаправление на маршрут ошибок.
}
}).catch(err=>{...})
}В предыдущем коде мы опустили импорты и шаблон, так как на данном этапе они должны быть тривиальными для читателя. Наш шаблон должен содержать как минимум поле для ввода email пользователя, второе поле для ввода OTP-кода, а также две кнопки для запуска по щелчку функции signInUser() и функции checkOTP().
Первая передаст письмо на бэкенд и будет ждать ответа с указанием времени ожидания в секундах, которое мы используем для запуска таймера (всегда полезно сообщить пользователю, сколько времени у него есть для ввода кода). В настоящее время для электронных писем и текстовых сообщений стандартом является 60 секунд.
Когда это происходит, мы также скрываем первое поле, а затем показываем форму ввода "OTP". Когда пользователь вводит код и нажимает Submit, активизируется функция checkOTP(), и мы снова передаем код на сервер, ожидая ответа. В случае успеха мы можем перенаправить пользователя в защищенную область в соответствии с логикой нашего приложения.
Учитывая тривиальность шаблона, для читателя будет хорошим упражнением самостоятельно создать компонент и шаблон. Затем возможное решение можно найти в примерах кода в папке Глава 5.
Следуя прогрессивному подходу к безопасности, следующим шагом является объединение предыдущих подходов в общий новый процесс: двухфакторная аутентификация (2FA), которую мы сейчас и рассмотрим.
2FA - двухфакторная аутентификация
В случае 2FA наше приложение объединяет два или более предыдущих подхода для проверки пользователя. Ключевая концепция этого метода заключается в том, что даже третьего лица или простого имени пользователя и пароля недостаточно, и пользователю необходимо иметь "вторичный фактор" для проверки - например, использование зарегистрированной электронной почты, номера телефона (для отправки кодов по SMS), приложений для аутентификации (например, Google Authenticator), USB-устройства, карты безопасности (с чипом или считывателем полос) и т.д.
Процесс работы прост, но требует от нашего бэкенда больше, чем от фронтенд-приложения. После того как SPA аутентифицирует пользователя с помощью любого из перечисленных ранее методов, на бэкенде запускается второй запрос для отправки соответствующего запроса на устройство безопасности. Предположим, что пользователь получает от нашего сервера SMS с кодом. Наш SPA будет ждать, собирать этот код в течение определенного промежутка времени (обычно 60 секунд) и отправлять его на бэкенд в определенную конечную точку. Именно сервер затем проверяет код.
В реальности это похоже на наличие двух или нескольких паролей, проверка которых производится каскадно. Если какой-либо шаг окажется неудачным, то вся операция будет отменена.
Вот визуализация этого процесса:
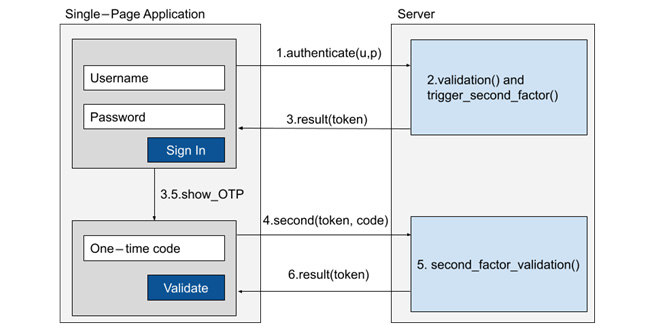
Рисунок 5.8 - Упрощенный вид взаимодействия SPA и сервера с 2FA.
Как видно из упрощенного рабочего процесса, процесс проверки пользователя с помощью 2FA (как и в случае с беспарольными и OTP-методами) зависит не столько от кода или специфической криптографии, сколько от использования продуманных средств коммуникации и изоляции данных. Данные и процесс проверки никогда не покидают наш сервер и не могут быть видны конечному пользователю, даже если открыть код нашего SPA. В некотором смысле этот рабочий процесс можно представить как объединение аутентификации по OpenID или учетным данным с последующей реализацией OTP.
Основная задача нашего приложения - собирать данные, составляющие каждый шаг, и передавать их на сервер. В промежутках между ними мы могли бы менять маршрут или обновлять интерфейс, но эта реализация тривиальна, поэтому конкретного кода мы здесь не увидим (как программно изменить маршрут, например, можно было посмотреть ранее).
В целом 2FA считается "более безопасным методом", но он не лишен недостатков и может подойти не для всех приложений. Например, что произойдет, если вы знаете свое имя пользователя и пароль, но потеряете второе устройство (мобильный украдут, взломают и т.д.)? Организации, использующие этот метод, часто предоставляют возможность восстановления идентификационных данных, нередко с дорогостоящей реализацией (вспомните банк и телефонную службу). В итоге этот метод создает еще один уровень сложности в аутентификации пользователей, а вместе с ним и еще одну возможную точку отказа, что при неправильном подходе приводит к разочарованию пользователей.
Далее рассмотрим еще один метод аутентификации, который набирает обороты в качестве нового ребенка в блоке шаблонов аутентификации: Web3-аутентификация.
Web3-аутентификация
Перед тем как перейти к рассмотрению этой темы, необходимо определить, что такое Web3. По всей видимости, существует некоторая путаница в определении, поэтому для наших целей Web3 считается следующей итерацией или эволюцией Интернета, где вычислительная мощность будет осуществляться на децентрализованных и распределенных серверах с использованием технологий блокчейн.
Наиболее известными и популярными приложениями этих технологий в настоящее время являются криптовалюты, децентрализованные самоуправляемые организации, децентрализованные финансы, игры типа "играй и получай", распределенные облачные хранилища и многое другое.
Блокчейн (англ. blockchain) - это бухгалтерская книга, которая ведется сетью распределенных компьютеров. Все, что записывается в неё, является неизменяемым и общедоступным для любого пользователя сети. Некоторые блокчейны являются "умными", то есть они могут содержать не только данные, но и запускать приложения, как и любой бэкэнд-сервис.
Фронтенд-приложения, подключаемые к блокчейну, называются распределенными приложениями (DApps), которые в большинстве своем являются SPA. Для решения этой задачи, как мы уже убедились, очень хорошо подходит фреймворк Vue 3. DApp должен соединяться с внутренним сервером, который является частью целевой сети блокчейна. Такие серверы называются узлами (nodes).
В некоторых случаях DApp может взаимодействовать непосредственно с блокчейном. Большинство, если не все, блокчейны используют криптовалюты для регулирования операций и вознаграждения узлов, поддерживающих сеть. Криптовалюты логически приписываются к уникальному идентификатору блокчейна, называемому "кошельком".
В этих кошельках реализованы весьма интеллектуальные криптографические технологии, позволяющие подтверждать друг друга при выполнении операций с помощью открытых и закрытых ключей. У пользователя может быть множество кошельков. В блокчейне не существует электронной почты или способов восстановления утерянных ключей, и каждый кошелек уникален.
Для того чтобы решить все эти проблемы с криптографическими знаками и валидацией, а также упростить работу пользователей, существуют специальные плагины для браузеров, называемые "цифровыми кошельками", а также мобильные приложения-кошельки, которые также реализуют просмотр веб-страниц.
Эти приложения хранят учетные данные и выполняют всю работу с блокчейном. Конечно, существует множество библиотек для выполнения тех же задач на чистом JavaScript, но это выходит за рамки данной книги. Далее мы рассмотрим, как в нашем SPA мы можем использовать возможности этих технологий для идентификации пользователя даже автоматически при посещении страницы нашего приложения.
Мы сосредоточимся на том, как сделать так, чтобы пользователь мог идентифицировать свою личность.
В качестве примера мы рассмотрим крупнейший смарт-блокчейн - сеть Ethereum. Аналогичный рабочий процесс с большим или меньшим количеством шагов применим и к другим сетям, использующим различные SDK, поэтому перенос или включение дополнительных блокчейнов не слишком далеко отстоит от наших примеров. Основной концептуальный рабочий процесс выглядит следующим образом:
Импортируем библиотеку для подключения к сети на нашем JavaScript, либо через такие библиотеки, как web3js, ethjs, либо использовать тот, который инжектируется непосредственно кошельком браузера - в нашем примере, MetaMask, в window.ethereum.
- Используя объект ethereum, мы запрашиваем у пользователя подключение его кошелька к нашему сайту и получаем адрес выбранного кошелька
- После этого наше приложение может отправить на бэкэнд идентификатор кошелька (который является публичным) и использовать его в качестве уникального идентификатора учетной записи пользователя
Как уже было сказано, мы будем использовать объект, инжектированный MetaMask, поскольку это один из наиболее известных браузерных кошельков. В данном случае здесь приведен код, запрашивающий кошелек текущего пользователя:
ethereum
.request({ method: 'eth_requestAccounts' })
.then(
result => console.log(result[0]),
err => console.log(err)
)Вот и все! Выделенная строка побуждает MetaMask открыть новое окно и запросить у пользователя разрешение на подключение его кошелька к вашему веб-приложению, а затем вернуть удобный промис. В случае разрешения результатом будет массив строк, в котором первой позицией будет адрес кошелька для текущей сети. В случае отказа будет выдана ошибка.
Совет
При использовании MetaMask можно открыть в браузере Инструменты разработчика и набрать в одной строке приведенный ниже код для его тестирования.
С помощью MetaMask тот же код для сети Ethereum также работает при подключении к сетям Polygon и Binance Smart Chain (три по цене одного!). Другие сети и кошельки, например кошелек Phantom, работают по тому же принципу и внедряют в объект windows новый объект .solana. Ознакомьтесь с документацией по целевому блокчейну, чтобы узнать подробности каждой реализации.
Взаимодействие с каждым блокчейном и его кодом выходит за рамки данной книги, поэтому мы ограничимся идентификацией пользователя по адресу его кошелька. Получив эту идентификацию, логика приложения должна сохранить ее для дальнейшего использования, поскольку она действует как идентификатор пользователя.
Для аутентификации и взаимодействия с несколькими блокчейнами существуют также решения сторонних разработчиков, и нам следует рассмотреть их, прежде чем реализовывать собственное решение.
Подведение итогов
В этой главе мы значительно улучшили наше приложение и создали продуманный SPA с навигацией с помощью маршрутизатора Vue. Это важная концепция, позволяющая сегментировать приложение и организовать работу между членами команды разработчиков. Фракционирование приложения по пути навигации упрощает разработку и сопровождение и делает их более организованными.
Мы также изучили несколько стандартных паттернов аутентификации, которые можно использовать в наших приложениях. Они охватывают большое количество сценариев, используемых сегодня в индустрии, начиная от самых простых имени пользователя и пароля и заканчивая новыми Web3 DApps.
Мы также уделили время тому, как работают стандартные протоколы, такие как OAuth, а также OTP, и как они могут быть реализованы для дополнительного уровня безопасности в качестве второго фактора аутентификации. Все эти навыки актуальны и необходимы для современных стандартов веб-приложений.
В следующей главе мы познакомимся с прогрессивными веб-приложениями (PWAs).
Вопросы для проверки
В этой главе мы рассмотрели множество различных тем и ввели новые понятия. Используйте следующие вопросы, чтобы закрепить полученные знания:
- Когда лучше использовать SPA вместо MPA и наоборот?
- Каковы преимущества использования маршрутизатора в SPA? Назовите не менее трех из собственного анализа.
- Как можно использовать представления для определения компоновки приложения?
- Как можно получить доступ к параметрам и строке запроса, переданным маршруту, в JavaScript?
- Каковы некоторые общие стандартные шаблоны для аутентификации пользователей?
- Каковы некоторые соображения безопасности при аутентификации пользователей в SPA?