Тестирование и системы контроля версий
Успех нашего приложения зависит от многих факторов, помимо качества организации кода или паттернов. Более того, сама природа программного обеспечения подразумевает, что во время и после разработки будут происходить изменения, меняться требования, область применения и т.д.
С каждой разработанной функцией в программное обеспечение вносится элемент сложности, создающий взаимосвязи и зависимости. Новые включения могут нарушить эти связи и внести разрывные изменения, привести к ошибкам или даже полностью вывести систему из строя.
Решением этой проблемы является отслеживание изменений кода и проведение тестов приложения для выявления проблем и максимального обеспечения соответствия системы желаемым атрибутам ПО и удовлетворения требований.
В этой главе мы рассмотрим, как можно более точно определить, что происходит в системе.
- Различные подходы к тестированию и концепция тестовой разработки (TDD)
- Установка тестового пакета (Vitest) и инструментов тестирования (Vue Test Utils) для нашего проекта
- Создание и запуск тестов на существующем проекте для синхронного и асинхронного кода
- Тестирование наших компонентов с помощью симуляции взаимодействия с пользователем
- Установка и управление нашим исходным кодом с помощью Git и онлайн-репозиториев, таких как GitHub или GitLab
Представленные в этой главе концепции являются введением в важные профессиональные навыки разработчика, обеспечивающие создание качественного программного обеспечения.
Часто эти задачи остаются в стороне или отходят на второй план. Однако их отсутствие может привести к дорогостоящим ошибкам и длительному переутомлению по мере роста сложности программного обеспечения.
Для нетривиальных приложений, в которых задействовано более одного разработчика, в настоящее время вряд ли можно представить себе проект, в котором не использовались бы некоторые из этих инструментов.
В этой главе мы сосредоточимся на Unit testing и инструментах, предоставляемых командой Vue для его выполнения.
Технические требования
Эта глава не имеет дополнительных требований по сравнению с предыдущими реализациями примеров кода. Окончательный исходный код можно найти в официальном репозитории этой книги по адресу https://github.com/PacktPublishing/Vue.js-3-Design-Patterns-and-Best-Practices/tree/main/Chapter09.
Посмотрите следующее видео, чтобы увидеть код в действии.
Что такое тестирование и TDD
Тестирование - это процесс проверки того, что программное обеспечение делает то, что должно делать, в соответствии с требованиями проекта.
Оно включает в себя ручное или автоматизированное выполнение инструментов для оценки и измерения различных свойств и атрибутов программного обеспечения, выявления ошибок и багов и предоставления обратной связи разработчикам для принятия мер по их устранению.
Существует множество различных подходов и типов выполняемых тестов, например, следующие:
- Unit testing: при этом соответствующие единицы исходного кода проверяются на соответствие ряду входных и выходных данных. Часто оно автоматизировано.
- Интеграционное тестирование: Все компоненты системы проверяются вместе как единое целое, при этом ищутся ошибки и недочеты в интеграции, взаимодействии и т.д.
- End-to-end (e2e) testing: предполагает полную проверку приложения, имитирующую его использование в реальных условиях, взаимодействие с базами данных, сетевые сценарии и т.д. Оно может проводиться как с помощью автоматизированных средств, имитирующих взаимодействие с человеком, так и вручную с использованием реальных пользователей.
Перечисленные виды тестирования - лишь малая часть этой дисциплины, поскольку существуют сотни возможных тестов, которые можно применить к программному обеспечению. В крупных компаниях могут существовать целые группы тестирования, занимающиеся обеспечением качества программного обеспечения.
Как правило, чем сложнее программное обеспечение, тем сложнее может быть и тестирование. На практике план тестирования может быть не менее сложным, чем сам план разработки. Как уже говорилось во введении, мы остановимся на официальных инструментах, предоставляемых командой Vue для решения этой задачи.
Тестирование может проводиться до, во время, после или параллельно с разработкой. TDD - это дисциплина, которая возлагает бремя тестирования как можно раньше в проекте, даже до начала фактического кодирования, с целью соответствия требованиям. Она включает в себя следующие этапы:
- Написание тестового случая, основанного на требованиях и дизайне приложения, с указанием ключевых входов и ожидаемых выходов.
- Запуск теста, который должен завершиться неудачей (поскольку код еще не написан).
- Напишите реальный код для тестирования (функцию, компонент Vue и т.д.).
- Запустите тест на созданном коде. В случае неудачи рефакторингуйте код или дизайн.
- Начните с нового тестового случая для следующего блока.
Этот процесс повторяется, и ожидается, что он обеспечит разработчикам значительное сокращение "багов" и ошибок и поможет им сосредоточиться на требованиях. Правда, это требует дополнительных усилий на ранних этапах проекта, в отличие от рефакторинга, когда тесты выполняются в конце.
TDD стал популярным в некоторых командах и с некоторыми фреймворками, и предполагается, что он поможет разработчикам улучшить свой собственный код, поскольку они теперь приобретают "тестирующее" мышление. Однако специальных исследований, подтверждающих это, не проводилось, но практикующие эту дисциплину отмечают, что она улучшила их код и дизайн. В связи с этим, конечно же, возникает вопрос: что нужно тестировать и как можно оптимизировать эту задачу в нашем рабочем процессе? Именно эту тему мы и рассмотрим далее.
Что тестировать
Одним из ключевых факторов успеха хорошего плана тестирования и его реализации является решение вопроса о том, что тестировать. Невозможно протестировать всю совокупность возможностей или 100% компонентов и взаимодействий в проекте с учетом внутренних и внешних факторов.
Даже попытка полностью охватить все возможности будет невероятно дорогой и практически невозможной. Вместо этого необходимо сосредоточиться на реальных возможностях того, что можно протестировать в рамках наших временных и бюджетных ограничений, тщательно отобрав нетривиальные элементы, которые "делают или ломают" наши требования к проекту. Зачастую это нелегкая задача.
Когда речь идет о Vue-приложениях, нам необходимо сосредоточиться на важнейших сервисах и компонентах, выполняющих ключевые операции. Нам необходимо протестировать следующее:
- Сервисы: Самостоятельные функции, как синхронные, так и асинхронные. Функции, которые не возвращают значения, но выполняют логические процедуры, будут служить для другого вида тестирования, чем то, которое мы рассмотрим здесь. Они будут связаны с имитацией сетевых взаимодействий или вызовов баз данных, политик приложения и т.д. Однако принципы их тестирования схожи.
- Компоненты: Нам необходимо тестировать входы (props) и выходы (events и HTML). Компоненты более высокого уровня, объединяющие другие компоненты для выполнения рабочего процесса или бизнес-логики, также могут быть протестированы аналогичным образом (props, events и HTML-вывод). Однако для них также потребуются другие виды тестирования, например, end-to-end тестирование.
Мы можем написать собственные функции и инструменты для выполнения тестов, но, за исключением некоторых крайних случаев, очевидной рекомендацией является использование стабильных тестовых наборов и инструментов.
В нашем случае для Vue существуют официальные ресурсы, предоставляемые той же командой, под названием Vitest и Vue Test Utils.
Использование тестового пакета/библиотеки имеет множество преимуществ, схожих с использованием фреймворка или библиотеки при "обычной" разработке приложения. Пожалуй, одно из главных преимуществ связано с DX, или Developer eXperience, поскольку они оптимизируют и облегчают процесс разработки, а в лучшем случае - делают его более легким.
Давайте научимся применять эти инструменты в нашем рабочем процессе на примере приложения, которое мы рассмотрим в следующем разделе.
Наш базовый пример приложения
Понимать дисциплину тестирования и знакомиться с инструментами лучше всего, применяя их на практике в реальном проекте. В качестве учебного упражнения мы сначала возьмем работающее приложение, основанное на одном из примеров, представленных в главе 2, Принципы и паттерны проектирования программного обеспечения.
Мы создадим калькулятор Фибоначчи и установим в проект тестовый пакет Vitest и утилиты Vue Testing Utils. Позже мы объясним, что изменится в этом подходе при применении дисциплины TDD.
Код этого приложения можно найти в репозитории к этой главе. После загрузки необходимо выполнить следующую команду для установки зависимостей:
$ npm installДля запуска приложения необходимо выполнить следующие действия:
$ npm run startПосле того как сервер будет готов, при загрузке сайта в браузере должно появиться приложение следующего вида:

Рисунок 9.1 - Пример приложения с калькулятором Фибоначчи
Данное приложение создано с целью изучения основ тестирования функций и компонентов, поэтому оно является очень базовым, но достаточным. Нам представлен один служебный файл (/src/services/Fibonacci.js) и три компонента: App.vue, FibonacciInput.vue и FibonacciOutput.vue.
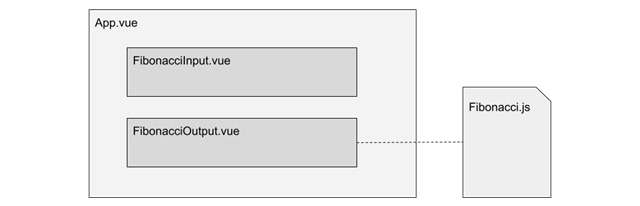
Рисунок 9.2 - Компоненты и сервис для приложения
Наш компонент уровня приложения, App.vue, получает от FibonacciInput.vue целое положительное число через событие, которое передает в качестве входного props в FibonacciOutput.vue.
Этот компонент использует сервис Fibonacci.js для вычисления соответствующего числа Фибоначчи, входящего в серию, и представления его пользователю. Как бы просто ни звучало это приложение, оно дает нам базовые примеры для создания тестов для наиболее распространенных случаев, что позволит нам взять уверенный старт. Теперь настало время установить наш тестовый пакет.
Установка и использование Vitest
Vitest - это тестовый пакет, то есть он предоставляет из коробки набор инструментов и фреймворк для выполнения тестов в нашем коде. Разработанный командами Vue и Vite, он легко интегрируется с Vite, даже имеет одну и ту же конфигурацию и уважает организацию друг друга.
Vitest можно выбрать при создании проекта Vue, выбрав соответствующую опцию в мастере создания - эта задача добавит папку /src/tests, несколько примеров и несколько дополнительных записей в наш файл package.json.
Но вся эта шаблонная информация может несколько сбить с толку, если у нас нет опыта работы в этой области. Вместо этого мы начнем с уже созданного проекта и установим Vitest в качестве зависимости разработки - задача, которая позволит нам понять, как он работает и организован.
Установите Vitest из командной строки в корневой каталог проекта с помощью следующей команды:
$ npm install -D vitestМенеджер пакетов потратит некоторое время на включение Vitest и всех необходимых зависимостей, но не изменит наш исходный код и его организации.
Для удобства мы будем использовать npm и для запуска наших тестов, поэтому нам нужно открыть наш файл package.json и в секции scripts ввести следующие строки, чтобы секция выглядела следующим образом:
"scripts": {
"start": "vite",
"build": "vite build",
"preview": "vite preview",
"test": "vitest",
"test:once": "vitest run",
"test:coverage": "vitest run --coverage"
}На этом этапе мы можем протестировать наш тестовый набор:
$ npm run testПосле выполнения этой команды вас любезно встретит красное сообщение о том, что тесты не прошли. Идеально. Так и должно быть, ведь у нас еще нет ни одного теста! Итак, давайте их добавим. Начнем с тестирования нашего сервиса Fibonacci.js.
Vitest позволяет нам писать наши тестовые функции в независимых файлах или in-source, то есть размещать их рядом с JavaScript нашего компонента.
В обоих подходах есть свои преимущества и недостатки, но для начала мы разместим наш тестовый код в независимых файлах, по одному для каждого сервиса и компонента. Таким образом, мы разместим эти файлы в собственной директории, которая по условию может быть либо /src/tests, либо /src/components/tests, но также может быть размещена рядом с однофайловыми компонентами или сервисами.
Vitest проверит всю папку с исходным кодом на наличие тестовых файлов. Несмотря на то, что мы можем очень творчески подойти к размещению этих файлов, мы поместим их в /src/test, чтобы все было аккуратно.
Существует еще одно соглашение, которого необходимо придерживаться: каждый тестовый файл должен иметь то же имя, что и тестируемый файл, плюс расширение .spec.js или .test.js. Vitest использует это соглашение для упорядоченной идентификации и запуска тестов. Так, в нашем случае сервис Fibonacci.js будет иметь аналог для тестирования в /src/tests/Fibonacci.test.js. Создайте этот файл и введите в него следующие строки:
/src/tests/Fibonacci.test.js
import { describe, expect, test } from "vitest"
import { Fibonacci, FibonacciPromise } from "../services/Fibonacci.js"В первой строке мы импортируем три функции из Vitest, которые лежат в основе всех наших тестов и которые мы будем использовать чаще всего. Вот что делает каждая из них:
- describe(String, Function): Эта функция объединяет несколько тестов, и Vitest выдает отчет о группе тестов, используя описание, заданное в качестве первого параметра. Вторым параметром является функция, в которой мы будем запускать тесты с помощью функции test().
- test(String, Function): Первый параметр - это описание тестов, входящих во второй параметр, который является функцией. Тест будет "пройден", если в нем не возникнет ошибок. Это означает, что мы можем написать собственную тестовую логику и инструменты, следующие этому условию, и выбрасывать JavaScript-ошибку при неудачной проверке. Однако есть и более простой подход.
- expect(value): Это функция, которая выполняет "магию" тестирования. В качестве уникального аргумента она получает единственное значение или функцию, приводящую к единственному значению. Результатом expect() является цепочечный объект, который открывает множество различных и почти естественных для языка утверждений (сравнений, валидаций и т.д.) для выполнения над значением аргумента. Под капотом он в некоторой степени использует синтаксис Chia, а также совместим с другими тестовыми наборами, таких как Jest - например, expect(2).toBe(2). Полный список всех возможных методов утверждения можно найти в официальной документации.
Во второй строке тестового файла мы напрямую импортируем две функции, содержащиеся в сервисе: Fibonacci() и FibonacciPromise(). Нам необходимо импортировать каждую функцию, которую мы хотим протестировать, а затем создать для каждой из них необходимое количество тестовых групп. Начнем с самостоятельной функции Fibonacci(), добавив следующую группу тестов:
describe("Test the results from Fibonacci()", () => {
test("Results according to the series definition", () => {
// Expected values as defined by the series
expect(Fibonacci(0)).toBe(0)
expect(Fibonacci(1)).toBe(1)
expect(Fibonacci(2)).toBe(1)
expect(Fibonacci(3)).toBe(2)
// A known value defined by calculation of the series
expect(Fibonacci(10)).toBe(55)
})
})Начнем с создания группы тестов с помощью describe() и создадим внутри переданной функции столько тестов, сколько потребуется. Внутри каждой функции test() мы можем создать столько утверждений, сколько необходимо, но в ней должно быть хотя бы одно.
Обратите внимание, как мы выполняем функцию из сервиса с различными аргументами, а затем утверждаем, что они соответствуют ожидаемому значению, определенному в числовом ряду. В данном случае мы используем .toBe() для проверки равенства, но точно так же мы можем проверять строки, объекты, типы и т.д., используя другие утверждения, такие как .not, .toEqual, .toBeGreaterThan и т.д.
В документации определено более 50 методов утверждений. Уделите некоторое время их изучению и помните, что они являются цепочечными, так что вы можете делать несколько утверждений одновременно. После сохранения этого файла можно запустить тест еще раз:
$ npm run testВы должны получить несколько сообщений зеленого цвета, указывающих на количество выполненных тестов и на то, прошли они или нет. В случае возникновения ошибки она будет выделена красным цветом с указанием текста описания и строки, в которой она возникла. Это сигнал к началу рефакторинга кода (при условии, что тестовая функция и утверждение были написаны правильно и корректно, иначе вы получите ложное срабатывание!)
В случае если ни один из методов утверждения не работает для конкретного случая, можно создать внутри test() свою собственную логику на обычном JavaScript и при неудачной проверке выдавать ошибку. Например, эти два фрагмента кода эквивалентны:
// Использование expect
expect(Fibonacci(10)).toBe(55);
// Использование собственной логики
let result = Fibonacci(10);
if (result != 55) throw Error("Вычисление не удалось");Несмотря на тривиальность примера, легко заметить, что первый случай с использованием expect() приводит к улучшению работы разработчика, поскольку он лаконичен, элегантен и легко читаем.
Тест все еще работает!
Возможно, вы заметили, что выполнение npm run test не завершает выполнение скрипта после окончания тестов. Как и в случае с сервером разработчика, Vitest продолжает ждать изменений в исходном коде или тестовых файлах и автоматически перевыполняет все тесты за вас. Если вы хотите запустить тесты только один раз, используйте npm run test:once или vitest --run, чтобы указать Vitest на однократный запуск тестов с последующим выходом.
Специальный случай утверждения - намеренная ошибка
Все предыдущие утверждения были сделаны с использованием "позитивного" подхода, согласно которому функция возвращает то, что ожидается. Использование "отрицательного" подхода в тестировании заключается в том, чтобы убедиться, что функция не сработает, когда это должно произойти.
Например, ряд Фибоначчи не определен для отрицательных чисел, поэтому любое вычисление не должно возвращать значение, а должно выдавать ошибку. В таких случаях необходимо обернуть выполнение функции в другую функцию, инкапсулировав ее, чтобы проверить утверждение на наличие выброшенной ошибки.
Это эквивалентно использованию блока try..catch в обычном JavaScript, чтобы не прерывать выполнение сценария при возникновении ошибки. Например, выполнение Fibonacci(-5) должно привести к ошибке, поэтому мы напишем наш тестовый пример так:
test("Out of range, must fail and throw an error", () => {
expect(() => Fibonacci(-5)).toThrow()
})Предыдущее утверждение сработает, как и ожидалось, не прерывая процесса тестирования.
Специальный случай утверждения - асинхронный код
Еще один особый случай, о котором следует помнить - это асинхронный код, такой как сетевые вызовы, промисы и т.д. В этом случае решением является использование async..await, причем не на функции, а на expect.
Например, чтобы протестировать асинхронную функцию FibonacciPromise(), мы напишем тест следующего вида:
test("Resolve promise", async () => {
await expect(FibonacciPromise(10)).resolves.toBe(55)
})Обратите внимание, что мы применяем синтаксис async ко всей функции test, а await - к функции expect(). Также нам необходимо использовать утверждение .resolves для указания успешного разрешения значения для проверки. Если бы нам нужно было проверить отказ Promise, мы бы использовали .rejects вместо .resolves.
Таким образом, мы рассмотрели большинство инструментов и подходов к тестированию для начала юнит-тестирования наших простых JavaScript-функций. Однако все эти тесты выполняются с помощью Node.js (серверной версии JavaScript), а не в браузере, где будут выполняться наши компоненты Vue. В Node.js нет объекта DOM или Windows, поэтому у нас нет HTML. Так как же нам тестировать наши однофайловые компоненты (SFC)?
Ответ заключается в том, чтобы предоставить Vitest симулированный DOM, в который мы можем установить наши компоненты и запустить тесты, как если бы это было окно браузера. Здесь на помощь приходят инструменты Vue Test Utils.
Установка Vue Test Utils
На данный момент Vitest предоставляет нам из коробки инструменты для тестирования обычных JavaScript-функций, классов, событий и т.д. Для тестирования однофайловых компонентов нам нужны дополнительные ресурсы, и они снова предоставляются нам официальной командой Vue в виде Vue Test Utils. Чтобы установить их, выполните следующую команду:
$ npm install -D @vue/test-utilsПосле завершения установки нам необходимо обновить файл vite.config.js, включив в него окружение, в котором будут тестироваться компоненты, то есть контекст браузера. Изменим конфигурационный файл так, чтобы он выглядел следующим образом:
export default defineConfig({
plugins: [vue()],
test: {environment: "jsdom"}
})Vitest и Vue Test Utils легко интегрируются с Vite, вплоть до того, что у них один и тот же конфигурационный файл. Теперь можно запускать тестовый набор, и Vitest попытается загрузить и установить все недостающие зависимости при первом запуске после этих изменений. Если по каким-то причинам установка jsdom не произошла автоматически, можно установить его вручную с помощью следующей команды:
$ npm install -D jsdomТеперь, с этими изменениями, мы готовы начать наши первые тесты компонентов. Начнем создавать файл для тестирования нашего компонента FibonacciOutput.vue, поскольку он является самым простым из тех, что есть в нашем приложении. Создайте в каталоге test следующий файл с таким кодом:
/src/tests/FibonacciOutput.test.js
import { describe, expect, test } from "vitest"
import { mount } from "@vue/test-utils" #1
import FibonacciOutput from "../components/FibonacciOutput.vue" #2
describe("Check Component props and HTML", () => {
test("Props input and HTML output", () => {
const wrapper = mount(FibonacciOutput,
{ props: { number: 10 } }) #3
expect(wrapper.text()).toContain(55) #4
})
})Приведенный код не сильно отличается от базового юнит-теста, который мы делали ранее, но некоторые вещи в нем выполняются несколько иначе.
В строке #1 мы импортируем функцию из библиотеки Vue Test Utils, которая позволяет нам "смонтировать" наш компонент в тестовой среде, имитирующей окно браузера с Vue 3.
В строке #2 мы импортируем наш компонент обычным способом, а затем, как и прежде, приступаем к написанию тестовой группы. Разница заключается в строке #3. Мы используем функцию mount для создания нашего живого компонента, передавая ее в качестве первого аргумента, а в качестве второго передаем объект со свойствами, которые будут применены к компоненту.
В данном случае мы передаем свойство number со значением 10. Функция mount вернет объект-обертку, представляющий наш компонент, раскрывая API, к которому мы обращаемся для выполнения наших утверждений. В данном случае в строке #4 мы проверяем, что обычный текст, выводимый компонентом, содержит значение 55, которое будет истинным при выполнении теста.
Именно с помощью этого объекта-обертки мы можем получить доступ к свойствам компонента, событиям, слотам и отображаемому HTML, обращаясь к соответствующим методам. В этой главе мы рассмотрим лишь некоторые из них, но полный список можно найти в официальной документации.
Этот короткий пример дает нам шаблон для написания наших тестов, но теперь мы перейдем к более сложному примеру для тестирования нашего компонента input. В каталоге test создайте следующий файл:
/src/tests/FibonacciInput.test.js
import { describe, expect, test } from "vitest"
import { mount } from "@vue/test-utils"
import FibonacciInput from "../components/FibonacciInput.vue"
describe("Check Component action and event", ()=>{
test("Enter value and emit event on button click",()=>{
let wrapper=mount(FibonacciInput) #1
wrapper.find("input").setValue(10) #2
wrapper.find("button").trigger("click") #3
// Захват параметров события
let inputEvents=wrapper.emitted("input") #4
// Утверждение, что событие было послано, причем с правильным значением
// Каждое событие содержит массив с переданными аргументами
expect(inputEvents[0]).toEqual([10]) #5
// или
expect(inputEvents[0][0]).toBe(10) #6
})
})Этот последний пример начинается так же, как и предыдущий, с импорта функций, которые мы будем использовать для описания тестов, монтирования нашего компонента и самого компонента.
Наша цель - в некоторой степени имитировать взаимодействие пользователя с компонентом, вводя значение в поле input, нажимая на кнопку, а затем программно перехватывая событие и переданное значение. Как и прежде, мы будем опираться на методы.
В строке #1 мы начинаем с установки нашего компонента и создания обертки. Обратите внимание, что в этот раз мы не передаем никаких опций, поскольку они нам не нужны. В строке #2 мы используем метод find() обертки, чтобы найти элемент input и установить для него значение 10.
Метод find() извлекает элементы с помощью строки с тем же синтаксисом, что и querySelector в окне браузера. Возвращаемый объект представляет собой обертку вокруг элемента, которая опять же открывает пользователям методы для взаимодействия с ним - в данном случае .setValue().
Используя аналогичную логику, в строке #3 мы также находим кнопку и вызываем событие click, которое приведет к появлению события input в нашем компоненте. Обратите внимание, как легко в строках #2 и #3 манипулировать нашим компонентом. Таким образом, мы можем обращаться к нему и взаимодействовать с ним программно, как это происходит в сквозном тестировании.
Теоретически мы могли бы создавать наши сквозные тесты с помощью этого инструмента, но есть и лучшие варианты, такие как Cypress, которые прекрасно работают с Vitest, предоставляя нам отличный DX.
В строке #3 мы нажали на кнопку, которая, как мы знаем, должна выдать событие. В строке #4 мы перехватываем все испускаемые события с именем input. В результате мы получаем массив обернутых событий, который можно использовать в наших утверждениях, ссылаясь на каждое событие по его порядковому индексу.
В данном случае мы запустили только одно событие, поэтому в строке #5 мы передаем его в ожидаемую функцию как inputEvents[0]. Однако обратите внимание, что утверждение приводит вывод к массиву [10], а не к значению, которое мы ввели в строке #2.
Почему так? Ответ заключается в том, что каждое событие имеет неопределенное количество аргументов, которые оно может передать, поэтому они фиксируются в массиве. Эквивалентная нотация показана здесь в строке #6, где мы передаем в expect() непосредственно значение первого элемента массива аргументов из первого захваченного события: inputEvents[0][0].
Затем мы можем непосредственно проверить результат на соответствие значению с помощью .toBe(10). Такой подход может показаться несколько запутанным и неуклюжим, когда приходится ссылаться на события и их значения, но он очень эффективен. Подумайте, что мы можем в одной строке утвердить полный массив с набором связанных значений!
В этих двух файлах мы протестировали ввод и вывод наших компонентов и даже подтвердили интерактивность, как и ожидалось. Мы также научились извлекать отрисованные элементы и получать доступ к их свойствам. Любая ошибка, возникшая в этих функциях, сделает тест недействительным и укажет нам правильное направление, строку и комментарий, где ее исправить. Размещение тестов в отдельных файлах - очень удобная альтернатива. Однако Vitest допускает и тестирование в исходном коде, что мы рассмотрим далее.
In-source тестирование
При тестировании в исходном коде мы можем указать Vitest на то, что тесты должны выполняться не в отдельных файлах, а в наших файлах JavaScript и отдельных компонентах. Эти альтернативы не исключают друг друга, поэтому мы можем одновременно использовать обе.
Причина этого заключается в том, что в некоторых случаях тестовый пример выгодно располагать "рядом" с исходным кодом, который он пытается проверить. Такой код должен быть помещен в конец нашего файла в следующем формате:
if (import.meta.vitest) {
const { describe, test, expect } = import.meta.vitest
//... Тестовые функции здесь
}Для того чтобы Vitest смог найти этот код в наших файлах, необходимо также изменить файл vite.config.js, включив в него следующее:
export default defineConfig({
test: {
includeSource: ['src/**/*.{js,ts}'],
// другие конфигурации здесь...
}
})И наконец, чтобы исключить тестовый код из производственной сборки, необходимо добавить следующее:
export default defineConfig({
define: { 'import.meta.vitest': 'undefined' }
// Другие конфигурации...
})В результате этих изменений мы можем включать тесты в конец наших JavaScript-файлов, получая при этом определенные преимущества и компромиссы. Например, если есть собственный сервис, который используется совместно или в разных проектах, то хорошей идеей будет разместить тесты в одном файле, а не дублировать их для каждого проекта.
Теперь, когда тесты готовы, давайте рассмотрим еще два преимущества использования Vitest: покрытие и живой (live) web UI.
Покрытие
Концепция покрытия очень проста и отвечает на вопрос о том, какая часть нашего кода покрывается автоматизированными тестами. Мы знаем, что 100%-ное покрытие возможно только для небольших приложений, поскольку те же усилия для больших проектов быстро попадают под закон убывающей отдачи.
Vitest предлагает нам простой способ ответить на этот вопрос, выполнив команду vitest -coverage. В нашем случае мы уже установили эту опцию в разделе скриптов package.json, поэтому мы можем выполнить следующую команду:
$ npm run test:coverageПри выполнении предыдущей команды, если какая-либо зависимость отсутствует, будет выдан запрос о том, хотим ли мы попытаться загрузить и установить ее:

Рисунок 9.3 - Vitest предлагает установить недостающие зависимости для покрытия
Для нашего примера кода главы отчет о покрытии должен выглядеть примерно так:
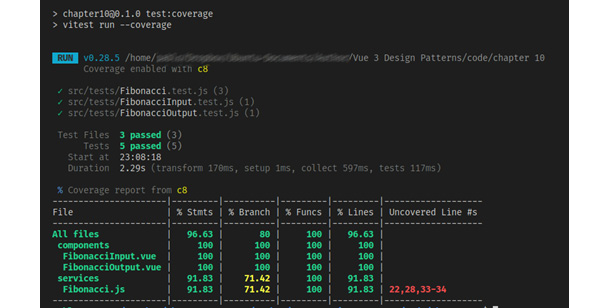
Рисунок 9.4 - Пример отчета о покрытии Vitest
При необходимости можно получить эту информацию в файле (в виде json, text или html). Для этого достаточно включить новую строку в наш файл vite.config.js:
test: {
coverage: {reporter: ['text', 'json', 'html']},
//...
}В результате повторного выполнения команды будет создан сайт, размещенный в новой директории coverage в корне нашего проекта. Этот статический сайт обеспечивает навигацию и углубление в отчет. В нашем примере он выглядит следующим образом:
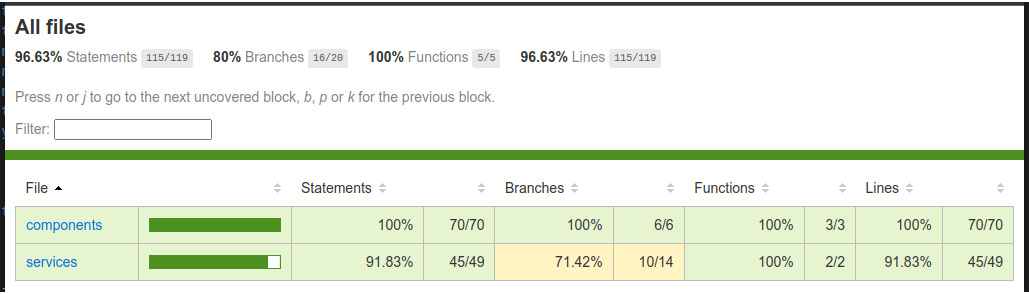
Рисунок 9.5 - HTML-отчет о покрытии
В зависимости от наших потребностей, этот простой инструмент может дать нам представление о нашем проекте, которое было бы трудно найти иным способом. Экспорт в JSON-файл также очень удобен, если нам необходимо интегрировать наш проект с другим программным обеспечением или форматом отчетности.
Есть и еще одна альтернатива, которая может пригодиться: Vitest также предоставляет веб-интерфейс для просмотра и взаимодействия с тестами в виде приборной панели. Мы рассмотрим это далее.
Интерфейс Vitest
Поскольку Vitest основан на Vite, он использует некоторые его возможности не только для живого тестирования, но и для создания сервера разработки, отображающего тесты в реальном времени. Чтобы воспользоваться этой возможностью, достаточно установить соответствующую зависимость следующим образом:
$ npm install -D @vitest/uiДля удобства в файл package.json следует добавить следующую строку, чтобы можно было запустить приложение с помощью npm:
scripts:{
"test:ui": "vitest --ui"
// Другие настройки...
}Затем мы можем запустить сервер с помощью командной строки:
$ npm run test:uiТестовый сервер разработки запустится и предоставит нам адрес для открытия в браузере. Для нашего приложения это выглядит следующим образом:
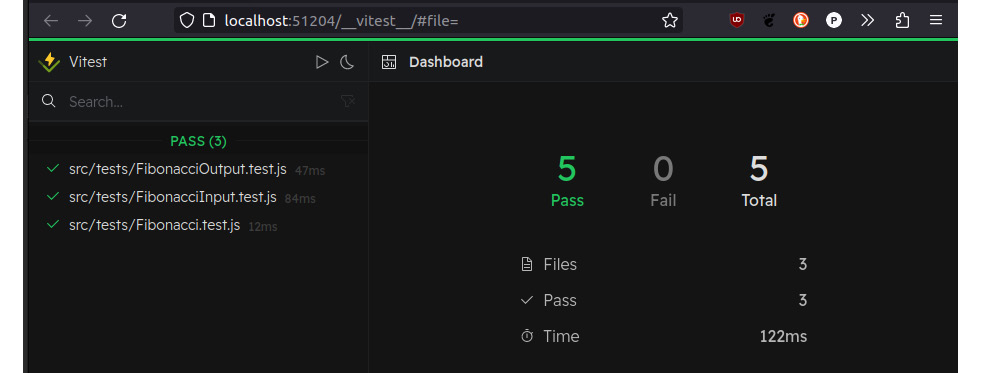
Рисунок 9.6 - Приборная панель пользовательского интерфейса Vitest
В веб-интерфейсе также появились новые возможности взаимодействия с тестовыми примерами и даже графического отображения взаимосвязей между компонентами и сервисами, вплоть до тестового кода.
После очистки кода и запуска тестов пришло время рассмотреть еще один инструмент для отслеживания изменений - фундаментальное понятие на сегодняшний день: контроль исходных текстов с помощью Git.
Что такое source control и зачем он нужен?
Разработка программного обеспечения - это "человекоемкая" дисциплина, то есть она в значительной степени зависит от креативности и вовлеченности разработчика, а также от его ноу-хау.
Принято пробовать разные подходы к одной и той же ситуации, писать и переписывать код. Даже процесс рефакторинга после тестирования подразумевает внесение изменений в код.
Не является аномалией, что в ходе этого процесса возникает необходимость "вернуться" к предыдущему коду, когда изменение или подход не оправдали ожиданий. Если мы постоянно перезаписываем одни и те же файлы, как отследить, что и где изменилось? И кто изменил? Нашей памяти не хватает, когда время и сложность растут.
Сохранять файлы с разными именами? Это очень скоро станет непрактичным. А как быть с объединением исходных текстов от нескольких разработчиков? Мы быстро видим, что управление исходным кодом нетривиальных проектов само по себе является очень важной задачей.
Историческим решением этой ранней проблемы в информатике было создание дополнительного программного обеспечения, отвечающего за отслеживание изменений в коде, позволяющего разработчику вернуться к своим следам и облегчающего работу по объединению кода от нескольких разработчиков для получения целостного исходного кода.
Появившаяся дисциплина для решения этой задачи называется Source Control (SC), а программное обеспечение для ее реализации - Source Control System (SCS) или Source Control Management System (SCMS).
Существовало и продолжает существовать множество различных систем, таких как Mercurial, Subversion, ClearCase, Git, BitKeeper.
Каждый из них имеет свои компромиссы. В частности, Git сегодня используется большинством проектов и разработчиков по всему миру. Статистика в Интернете показывает разные процентные соотношения для наиболее популярных из них, но каждая из них демонстрирует такую тенденцию. В связи с этим нам важно научиться использовать Git, о чем и пойдет речь в нашей следующей теме.
Управление исходными текстами с помощью Git
На сегодняшний день самой популярной SCS является Git, созданный Линусом Торвальдсом, который также является создателем ядра Linux.
История гласит, что проект ядра Linux использовал BitKeeper для контроля исходного кода, но с ростом сложности и распределенности разработки команда столкнулась с множеством проблем. Разочаровавшись, Линус Торвальдс решил создать свою собственную SCS для решения реальных проблем, и на это у него ушли одни выходные! (источник).
Так было положено скромное начало Git'у, и с тех пор он стал популярен как в сообществе разработчиков открытого кода, так и в корпоративном мире.
Git - это распределенная СУБД, простая и эффективная в использовании из командной строки. Он предлагает следующие возможности:
- Создает и управляет репозиторием, где собирает исходные файлы и историю изменений для каждого из них.
- Позволяет совместно использовать проекты путем клонирования удаленных репозиториев в локальные проекты.
- Позволяет разветвлять и объединять проект. Это означает, что вы можете иметь разные копии одного и того же проекта с разным кодом (разветвление (branch)), переключаться между ними, объединять их и объединять по запросу (слияние (merge)).
- Синхронизирует изменения в проекте.
- Синхронизирует изменения из удаленного репозитория в локальную копию (называется pull).
- Отправляет локальные изменения в удаленный репозиторий (называется push).
Давайте научимся использовать Git, применив его к нашему текущему проекту для этой главы. Начнем с его установки в нашей системе, чтобы он был доступен для всех наших проектов.
Установка в системах Windows
Самым простым и рекомендуемым способом установки Git на Windows-системы является загрузка инсталляторов с официального сайта Git. Выберите нужную версию в соответствии с операционной системой (32- или 64-битная), а затем запустите программу установки, следуя инструкциям.
Рисунок 9.7 - Официальные программы установки Git для Windows
После завершения установки инструменты командной строки будут установлены на вашу систему, и мы сможем запускать их через терминал. Кроме того, если вы используете редактор кода, например Visual Studio Code, он интегрирует инструменты и предоставит вам графический интерфейс для выполнения основных операций.
Установка в системах Linux
В системах Linux установка производится через командную строку с использованием менеджера пакетов дистрибутива. Имя пакета в (почти) всех дистрибутивах - просто git. В системах Debian и Ubuntu установку можно запустить следующим образом:
$ sudo apt install gitОднако в этих дистрибутивах может быть не самая последняя версия, поэтому, если вам нужен последний стабильный релиз, необходимо добавить официальный PPA-репозиторий. В этом случае выполните следующие команды по порядку:
$ sudo add-apt-repository ppa:git-core/ppa
$ sudo apt update
$ sudo apt install gitПредыдущие команды обновят системные зависимости и установят (или обновят) Git на вашу систему. Полный список дистрибутивов и команд для установки Git можно найти в официальной документации.
Установка в системах macOS
В системах macOS существуют различные способы установки Git:
- Если у вас установлен Homebrew, выполните команду $ brew install git в Терминале
- Если вместо этого у вас установлен MacPorts, выполните команду $ sudo port install git в Терминале
- Если вы установили Xcode, Git входит в комплект поставки
Другие альтернативы можно найти в официальной документации.
Использование Git
Независимо от того, на какой системе вы работаете и какой тип установки вы сделали, Git будет установлен в ваш локальный путь, так что его можно будет запустить из любого окна терминала. Чтобы проверить установку и версию, выполните следующую команду (не требует прав администратора):
$ git --versionНа момент написания статьи текущей стабильной версией является 2.39.2. После этого откройте окно терминала в корневой папке нашего проекта. Чтобы начать использовать Git, нам необходимо создать локальный репозиторий с помощью следующей команды:
$ git initПосле выполнения в папке будет создан новый скрытый каталог. Вам не нужно беспокоиться об этом, поскольку он будет управляться Git'ом. Если в File Explorer отключена опция просмотра скрытых файлов, то вы можете не заметить его создания. Рекомендуется активировать в системе функцию Показать/просмотреть скрытые файлы.
После создания репозитория можно приступать к его использованию. Работа с файлами обычно включает в себя следующие этапы:

Рисунок 9.8 - Этапы работы с Git
После того как файлы созданы или отредактированы, следующим шагом является их "постановка (stage)". Это указывает Git'у на необходимость отслеживания изменений и включения файла в следующее событие фиксации. Commit - это акт перемещения этих файлов/изменений в хранилище. Если файл не поставлен на хранение, он не будет включен в коммит. Чтобы добавить файл, выполните следующую команду:
$ git add [filename1] [filename2]...Это добавит файлы, но будет довольно многословным. Если вы хотите добавить все изменения во все файлы, выполните следующее:
$ git add .Это пригодится при первой фиксации, когда репозиторий будет инициализирован. После выполнения этой команды все файлы начнут отслеживаться. Однако мы не хотим отслеживать все, что находится в нашей корневой папке, поэтому для исключения файлов или каталогов можно использовать специальный файл .gitignore. Если открыть этот файл в каталоге с примером, то получится примерно следующее:
/chapter 10/.gitignore
logs
*.log
npm-debug.log*
yarn-debug.log*
yarn-error.log*
pnpm-debug.log*
lerna-debug.log*
node_modules
dist
dist-ssr
*.local
.vscode/*
!.vscode/extensions.json
.idea
.DS_Store
*.suo
*.ntvs*
*.njsproj
*.sln
*.sw?Это обычный текстовый файл, который указывает Git'у не отслеживать файлы и каталоги, указанные в каждой строке. Вы также можете использовать подстановочные знаки, такие как звездочка (*) и вопросительный знак (?), для включения шаблона совпадения. Это очень полезно, поскольку существуют части кодовой базы, которые не нужно отслеживать, например, зависимости и бинарные файлы (изображения и т.п.). Убедитесь, что этот файл есть в вашей директории, прежде чем делать массовый staging.
После того как файлы будут помещены в stage, вы можете проверить их с помощью следующей команды:
$ git statusВ случае нашего примера проекта это будет выглядеть примерно так:
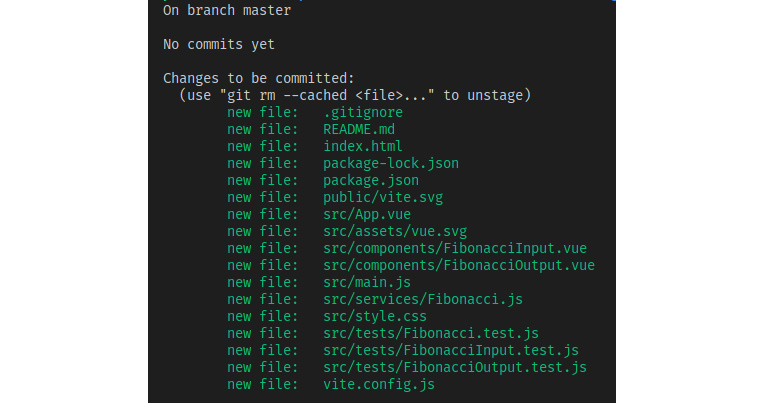
Рисунок 9.9 - Первая постановка в Git
Обратите внимание, что Git также сообщает нам, что мы находимся в ветке (branch) master, и что в нее еще не было сделано ни одного коммита.
Ветка master является основной веткой для нашего кода и создается по умолчанию. Это специальная ветка, которая используется для хранения стабильного кода наших приложений. В таких инструментах, как GitLab и GitHub (о них мы поговорим позже), эти ветки также вызывают определенные события после фиксации (commit). А пока давайте двинемся дальше и создадим нашу первый commit с помощью этой команды:
$ git commit -m "Первая фиксация"Мы увидим следующие результаты:
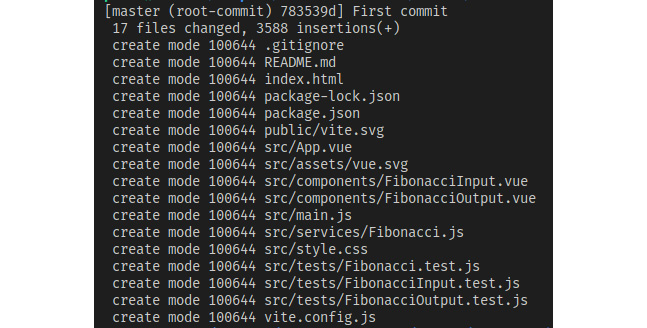
Рисунок 9.10 - Результаты первой фиксации
С помощью этих простых строк мы начали следить за своим исходным кодом. Теперь, как уже говорилось, мы закоммитили наш исходный код в ветке master. Git позволяет сделать мгновенную копию состояния нашего кода, подобно снимку экрана, и продолжить работу с этого места, не затрагивая оригинал. Это называется ветвление (branching) и является важной частью использования Git.
Управление ветвями и слияниями
Использование ветвей для управления разработкой - очень хороший способ двигаться вперед на определенной основе. Ниже приведены наиболее распространенные команды для управления ветвями:
| Действие | Пример команды |
|---|---|
| Создайте ветку и переключитесь на нее | $ git checkout -b [branch_name] |
| Создать ветку, но остаться в текущей | $ git branch [branch_name] |
| Удаление ветки | $ git branch -d [branch_name] |
| Переход к ветке | $ git checkout [branch_name] |
| Слияние ветки с текущей | $ git merge [branch_name] |
| Проверка текущей ветки | $ git branch |
Переместившись в другую ветку, вы можете выполнять все обычные операции Git (редактировать и удалять файлы и т.д.), не затрагивая другие ветки.
Конфликты при слиянии
При слиянии нескольких веток вместе или с master возможно и более чем вероятно, что некоторые файлы будут иметь расхождения с текущей веткой. В этом случае слияние (merge) завершится неудачей, и пользователю будет предложено устранить различия.
Git делает следующее: помечает целевой файл (файл в текущей ветке) маркерами в тексте, которые пользователь может редактировать. Как только они будут отредактированы, файл может быть размещен и зафиксирован, тем самым завершая слияние. Давайте попробуем сделать это без кода, специально создав несоответствие, которое нужно исправить. Выполните следующие шаги:
- Создайте новую ветку,
dev, с помощью этой команды:$ git checkout -b dev. - Отредактируйте
index.html, добавив в строку 11 (перед тегом script) следующее:<div>A div created in branch dev</div>. - Сохраните файл, поместите его в stage и закоммитьте изменения командой
$ git add index.html, а затем$ git commit -m "added div in dev". - Сейчас мы перейдем на ветку
masterс помощью$ git checkout master. - Заметьте, что строка 11 с div исчезла из
index.html. Это связано с тем, что данная редакция в этом файле так и не была сделана. Теперь добавьте в эту строку следующее:<p>Это изменение было сделано в master</p>. - Сохраните файл, выполните stage и закомитьте его с другим сообщением (см. шаг 3).
Теперь мы попытаемся объединить обе ветки, и, поскольку index.html был закоммичен в обеих с разным кодом, это не удастся! Чтобы начать слияние, выполните команду $ git merge dev.
В терминале появится сообщение об ошибке, а в index.html добавятся новые строки, указывающие на несоответствия. В нашем примере кода это выглядит следующим образом:
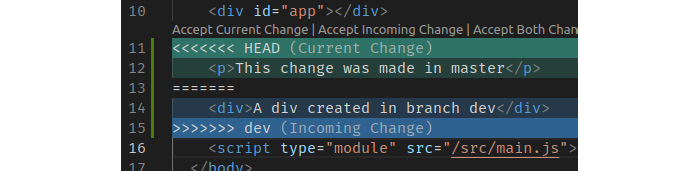
Рисунок 9.11 - Конфликт слияния
- Для устранения конфликта достаточно отредактировать исходный код по своему усмотрению (также удалить лишние метки, добавленные Git'ом), затем сохранить файл, поставить его и, наконец, сделать коммит. Вы получите сообщение о том, что слияние было разрешено.
Работа с ветвями и разрешение слияний при их появлении - обычная и довольно полезная практика, но мы все еще не используем весь потенциал Git'а. Как вы помните, Git - это распределенная СУБД, и здесь используется ее огромный потенциал. Введём удаленный репозиторий.
Работа с удаленными репозиториями
Подобно тому, как мы работаем с локальным репозиторием, Git может синхронизировать код с удаленным репозиторием. Это позволяет членам команды из любой точки мира совместно работать над одной и той же кодовой базой, разрешать конфликты, а также синхронизировать свой код с чужим. Работа с удаленным репозиторием включает в себя следующие шаги по настройке:
- Необходимо создать удаленный репозиторий и указать URL для подключения к нему.
- Добавляем удаленный репозиторий как новый origin в наш локальный репозиторий следующей командой:
$ git remote add origin URL- Настраиваем нашу ветку master на синхронизацию с удаленным репозиторием:
$ git push -set-upstream origin master- Получаем изменения из удаленного репозитория:
$ git pull origin master- Отправляем изменения в удаленный репозиторий:
$ git push origin masterПосле начального выполнения шагов с 1 по 3, дальнейшая работа будет включать шаги 4 и 5. Эти действия позволят поддерживать локальный репозиторий в синхронизированном состоянии с удаленным репозиторием. На практике современные IDE, такие как Visual Studio Code, уже предоставляют графические средства для выполнения этих операций, что повышает удобство работы над проектом. Они также включают в себя визуальные средства для разрешения конфликтов во время слияний.
Настройка Git-сервера для локальной сети выходит за рамки данной книги, но это введение было бы неполным без слов о GitHub и GitLab. Обычно, когда люди впервые слышат о Git, они ассоциируют его с GitHub, что вполне объяснимо, поскольку последний гораздо более популярен в средствах массовой информации.
GitHub - это не Git. Это веб-платформа, предоставляющая инструменты, построенные поверх Git, для размещения онлайн-проектов, содержащих удаленные репозитории. Таким образом, вы можете прекрасно работать с Git локально и синхронизироваться с удаленным репозиторием GitHub или GitLab. Это наиболее распространенный случай.
GitHub предоставляет средства обмена сообщениями и документацией, а также многое другое - даже дополнительные сервисы, позволяющие при обнаружении событий в вашем репозитории вызывать определенные действия и сервисы, некоторые из которых предоставляются локально (за отдельную плату), другие - удаленно (например, webhooks).
Например, можно сделать локальный коммит, выложить изменения в ветку master на GitHub и запустить целый набор процедур, от компиляции до деплоя на сайт.
Опять же, управление всеми этими возможностями выходит за рамки нашей главы, но важно помнить, что все это основано и построено на Git, поэтому, если вы понимаете, как работает и что делает Git, у вас будет прочная основа для дальнейшего использования других инструментов и сервисов. Есть еще одно понятие, ставшее привычным в этой теме, - непрерывная интеграция и доставка, которое мы рассмотрим далее.
Непрерывная интеграция и доставка
Непрерывная интеграция (Continuous Integration (CI)) - это практика, реализуемая с помощью рассмотренных нами технологий, при которой разработчики как можно чаще фиксируют свои изменения в центральном (удаленном) репозитории. Центральный репозиторий обнаруживает поступившие изменения и запускает автоматические тесты на код. Затем он компилирует/сборку конечного продукта. Это происходит непрерывно, в отличие от практики слияния и компиляции в определенную дату перед запуском.
Непрерывная доставка.
Непрерывная доставка (Continuous Delivery (CD)) строится на основе CI и предполагает развертывание выпущенного продукта в конечном месте. Вы можете настроить этот процесс на создание предварительных версий программного обеспечения или веб-приложений (например, бета-версий, ночных сборок и т.д.), а также запрограммировать дату выпуска для конечного размещения и доставки клиентам (иногда эта последняя часть может включать в себя отдельный процесс и называется Continuous Deployment). Оба упомянутых ранее сервиса (GitHub и GitLab) предлагают подобные услуги.
Используя эти концепции, можно организовать целый автоматизированный рабочий процесс от рабочего стола до Интернета, где простой Git-коммит и push на сервер запускают тестирование приложения и его публикацию в Интернете. Способ реализации этого рабочего процесса зависит от инструмента, используемого для реализации CI и CD.
Подведение итогов
В этой главе мы рассмотрели очень важные понятия, касающиеся заботы о качестве нашего кода.
Мы узнали, как устанавливать официальные инструменты для выполнения автоматизированных тестов в нашем коде и компонентах, а также как отслеживать изменения и управлять ими в исходном коде. Хотя приведенные здесь примеры и информация носят ознакомительный характер, они достаточно подробны для того, чтобы применять их в собственных проектах и постоянно расширять свои познавательные навыки.
Концепции CI и CD, а также сервисы, предоставляемые онлайновыми репозиториями, также дают прочную основу для их освоения, поскольку все они основаны на функциональности, предоставляемой Git'ом.
Все эти инструменты имеют профессиональную ценность для разработчика и необходимы в современной индустрии.
Вопросы для проверки
- Почему важно автоматизированное тестирование? Устраняет ли оно необходимость проведения ручного тестирования?
- Что необходимо для тестирования наших однофайловых компонентов в Vue?
- Что такое source control, и почему он необходим?
- Что такое Git, и чем он отличается от GitHub/GitLab?
- Когда вы изменяете файл в ветке, изменяется ли он во всех остальных ветках? Почему это происходит или не происходит?
- Одинаковы ли команды для управления Git'ом на всех платформах?
- Что означают термины CI и CD, и какую ценность они добавляют в рабочий процесс?