Многопоточность с Web Workers
В этой главе мы рассмотрим важные темы, которые позволят значительно повысить производительность веб-приложений, особенно одностраничных. Во-первых, мы узнаем, как работают веб-сайты и JavaScript, а также как использовать web workers для повышения эффективности вычислительной мощности приложения, доступа к данным и сетевых коммуникаций. Затем мы представим два новых концептуальных шаблона проектирования и реализуем их в примере приложения вместе с другими шаблонами, с которыми мы уже познакомились ранее.
Кроме того, мы представим две библиотеки, которые облегчат нам сетевые коммуникации, а также работу с постоянной базой данных (базами данных) в IndexedDB. Мы также реализуем простой сервер Node.js для обеспечения обратной связи и тестирования нашей работы в архитектуре с высокой степенью разобщенности, где наши фронтенд- и бэкенд-сервисы взаимодействуют с помощью стандартных API по протоколу HTTP.
В этой главе мы рассмотрим следующие темы:
- Web workers
- Шаблон проектирования Business delegate
- Сетевое взаимодействие внутри Web Worker
- Встроенная база данных браузера - IndexedDB
- Как построить простой Node.js API-сервер для тестирования
Концепции, изложенные в этой главе, можно считать "продвинутыми", но мы сведем их к понятным фрагментам, которые можно будет сразу же реализовать. К концу этой главы вы будете иметь твердые знания о том, как реализовать многопоточность в своих веб-приложениях, а также эталонный фреймворк для масштабирования и облегчения использования сложных браузерных API.
Технические требования
Эта глава не добавляет дополнительных требований к нашему приложению. Однако мы увидим только соответствующие части кода, поэтому, чтобы увидеть работу всего приложения, следует обратиться к примерам кода для главы 8, Многопоточность с Web Workers, в GitHub-репозитории книги https://github.com/PacktPublishing/Vue.js-3-Design-Patterns-and-Best-Practices/tree/main/Chapter08.
Посмотрите следующее видео, чтобы увидеть код в действии.
Введение в Web workers
JavaScript является однопоточным языком, то есть в нем нет возможности порождать процессы в отдельных потоках. Это заставляет браузеры запускать JavaScript на веб-странице в одном потоке с другими процессами, что напрямую влияет на производительность страницы, в первую очередь на процесс рендеринга, отвечающий за отображение страницы на экране.
Браузер прилагает значительные усилия для оптимизации работы всех этих движущихся частей, чтобы сделать страницу отзывчивой, производительной, быстрой и эффективной. Однако есть задачи, которые веб-приложение должно выполнять на JavaScript, которые являются тяжелыми и потенциально "блокирующими рендеринг".
Это означает, что браузеру придется обратить внимание на результаты работы кода и использовать все ресурсы для завершения выполняемой функции, прежде чем он сможет сосредоточиться на рендеринге (отображении страницы на экране). Если вы обнаружили на веб-странице процесс, из-за которого сайт кажется "неотзывчивым" или "тормозящим" после начала выполнения какого-либо действия (в некоторых случаях мышь может даже застыть), это может быть одной из причин.
Если открыть инструменты разработчика в современном браузере, то можно получить доступ к некоторым инструментам производительности для анализа поведения веб-страницы и времени, которое занимает каждый шаг процесса.
Например, вот быстрый вид первой загрузки YouTube по общей ссылке в Firefox для Linux:
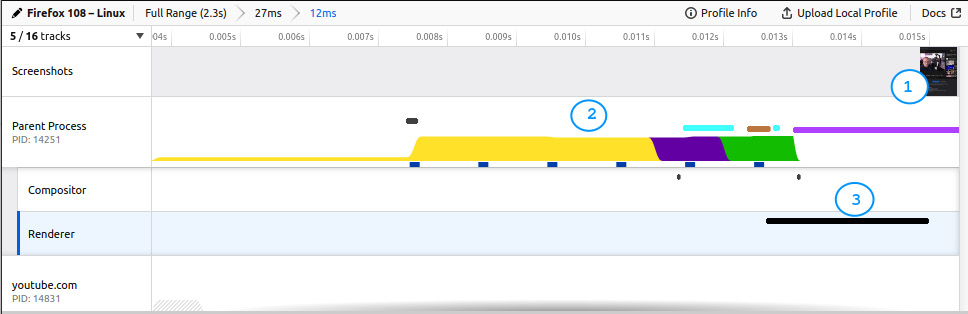
Рисунок 8.1 - Производительность первой загрузки YouTube при использовании инструментов разработчика
На предыдущем скриншоте мы увеличили масштаб обработки страницы, показав, что происходит до первого рендеринга, то есть до того, как пользователь увидит что-то на экране. Это представлено в первой строке Скриншоты, где для данного случая первые видимые элементы появляются в конце временной шкалы (#1).
Вторая строка показывает, чем занят основной Parent Process, и если вы обратите внимание, то самая первая секция (#2) посвящена обработке JavaScript. Процесс Renderer , выделенный и отображаемый черной полосой (#3), не может начаться до тех пор, пока не будет запущен JavaScript.
Когда он запускается, он рисует страницу на экране, и вы получаете видимое содержимое из #1. Это дает примерное представление о том, какую работу выполняет браузер в каждом цикле между рисованиями на экране (так называемыми "кадрами"). Браузер старается делать как можно больше кадров в секунду (fps). Чтобы поддерживать 60 кадров в секунду, он должен выполнять всю эту обработку примерно за 16,67 миллисекунды или меньше.
В лучшем случае процесс JavaScript должен быть решен за половину этого времени, чтобы сохранить плавность восприятия для пользователя. Что же происходит, когда обработка JavaScript занимает больше времени? Все просто: процесс рендеринга откладывается, fps падает и может возникнуть застывший пользовательский интерфейс (UI). В зависимости от особенностей вашего веб-приложения это может стать серьезной проблемой.
Вы можете сказать: "Минуточку, а почему бы нам не сделать тяжелые задачи асинхронными? Разве это не решит проблему?". Ответ: и может, и нет. Когда вы объявляете асинхронную функцию, это означает лишь то, что ее выполнение будет отложено до того момента, когда обработка последовательного кода будет завершена.
Скорее всего, это сдвигает асинхронный код к концу или после выполнения последовательного кода, но затем он будет выполняться последовательно, как обычно. Если процесс рендеринга происходит раньше, то вы можете ощутить прирост производительности, но если нет, то вы столкнетесь с той же проблемой, если асинхронная функция будет выполняться дольше (так как это повлияет на следующий рендеринг).
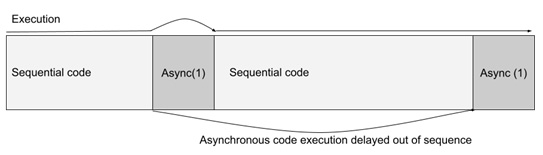
Рисунок 8.2 - Представление выполнения асинхронного кода, перенесенного после выполнения последовательного кода (1)
Тогда, если асинхронные операции не решат проблему производительности полностью, как ее решить? Помимо всех возможных оптимизаций, есть одна технология, которую также следует рассматривать в начале списка альтернатив: Web workers API.
Web workers - это JavaScript-скрипты, выполняющиеся в собственном процессе (или потоке, в зависимости от реализации), что позволяет не нарушать родительский процесс, в котором происходит рендеринг.
API браузера предоставляет довольно простой, но эффективный способ связи с родительским процессом и обратно: систему сообщений. Эти сообщения могут передавать только сериализуемые данные. Родительский процесс и каждый web worker работают в своем окружении и в своих границах памяти, поэтому они не могут совместно использовать ссылки или функции, поэтому все данные, передаваемые между ними, должны быть сериализуемыми, поскольку они копируются в каждый процесс.
Хотя это может показаться недостатком, на самом деле при правильном использовании это преимущество, в чем мы вскоре убедимся. Еще одним недостатком этой архитектуры является то, что web workers не имеют доступа к документной объектной модели (DOM) или объектам Window и, соответственно, к любым их сервисам. Однако они имеют доступ к сети и IndexedDB.
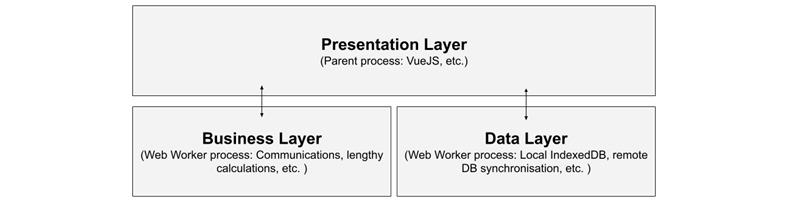
Рисунок 8.3 - Послойное представление приложения Vue с фоновыми процессами, использующими web workers.
Как видно из предыдущей диаграммы, мы можем инстанцировать несколько web workers для представления различных типов слоев в нашем приложении (Бизнес, Данные, Коммуникация и т.д.). Хотя web worker может запускаться и завершаться из родительского процесса по своему усмотрению, оба эти действия требуют больших вычислительных затрат, поэтому рекомендуется, чтобы созданные web workers оставались активными в течение всего времени работы приложения и обращались к ним по мере необходимости.
Также не рекомендуется злоупотреблять этим ресурсом, создавая "слишком много" web workers, поскольку каждый из них является отдельным процессом со своими собственными ресурсами. Четкого определения того, что такое "слишком много", не существует, поэтому рекомендуется проявлять осторожность. По моему опыту, если количество web workers не превышает однозначных значений, то даже на маломощных устройствах ваше приложение будет работать с отличной производительностью. Как и во многих других вещах, хорошего может быть слишком много, и это относится и к web workers.
Теперь, когда мы знаем, что такое web workers и чем они могут быть полезны, давайте посмотрим, как реализовать их на чистом JavaScript, а затем как сделать это с помощью Vite.
Реализация web worker
Создание web worker на чистом JavaScript довольно простое и понятное. Объект window предоставляет конструктор, правильно названный Worker, который получает в качестве параметра путь к файлу сценария. Например, если учесть, что наш web worker содержится в файле my_worker.js, то создать его можно следующим образом:
if (window.Worker) {
let my_worker = new Worker("my_worker.js")
...
}Достаточно просто, если конструктор существует в объекте window, то мы просто создаем нового web worker, обращающегося к конструктору напрямую. Вновь созданный web worker предоставляет простой API:
- .postMessage(message): Отправить сообщение на web worker. Это может быть любой тип данных, который может быть сериализован (основные типы данных, массивы, объекты и т.д.).
- .onmessage(callback(event)): Это событие срабатывает, когда web worker получает сообщение от родительского процесса. Полученное событие имеет поле .data, которое содержит сообщение/данные, переданные web worker.
- .onerror(callback(event)): При возникновении ошибки в web worker, срабатывает это событие, которое будет содержать следующие поля:
- .filename: Имя файла скрипта, сгенерировавшего ошибку.
- .lineno: Номер строки, на которой произошла ошибка.
- .message: Строка, содержащая описание ошибки.
Эта система обмена сообщениями позволяет нам осуществлять то, что в противном случае могло бы быть очень сложной формой межпроцессного взаимодействия (IPC). После ее внедрения наш предыдущий код должен выглядеть следующим образом:
let my_worker = new Worker("my_worker.js")
my_worker.onmessage = event => {
// обрабатываем сообщение здесь
console.log(event.data)
}
my_worker.onerror = err => {
//обрабатываем ошибку здесь
}
my_worker.postMessage("Привет от родительского процесса");Для завершения этой работы нам необходимо реализовать скрипт my_worker.js. Для данного примера он может быть таким простым:
./my_worker.js
self.onmesssage = event => {
console.log(event.data)
})
setTimeout(() => {
self.postMessage("Привет от web worker")
},3000)Наш пример web worker очень прост. Он печатает полученные данные в консоль, а через 3 секунды после активации отправляет сообщение родительскому процессу.
Обратите внимание, что мы используем зарезервированное слово self. Оно необходимо при обращении к API изнутри функции, так как ссылается на сам web worker. Именно поэтому оно необходимо внутри обратного вызова setTimeout. На корневом уровне он необязателен, поэтому можно написать self.onmessage, как в нашем примере, или непосредственно onmessage.
Web workers могут инстанцировать других web workers, а также импортировать другие скрипты с помощью метода self.importScript() или просто importScript(). Этот метод получает в качестве параметра строку с именем файла скрипта. Это аналогично тому, как мы используем оператор import в наших сервисах и компонентах в основном приложении.
При использовании Vite, как мы это делаем для создания нашего Vue-приложения, у нас есть альтернативный способ импорта и создания web worker с помощью суффикса. Например, добавьте следующее в наш скрипт main.js:
./main.js
import MyWorker from "my_worker.js?worker"
const _myWorker = new MyWorker()
_myWorker.postMessage("Hi there!")
_myWorker.onmessage = (event) => {...}При использовании суффиксальной нотации worker Vite оборачивает реализацию в конструктор, который мы можем использовать для инстанцирования нашего web worker. Такой подход делает работу с web workers более похожей на работу с любым другим классом в нашем приложении, поскольку мы можем использовать тот же подход для включения его в наше приложение, и именно этот синтаксис мы будем использовать в наших примерах.
Кроме того, Vite будет обрабатывать скрипты нашего web worker, поэтому мы можем использовать более привычный синтаксис для импорта ресурсов (import ... from ...) вместо родного self.importScript().
Еще много интересного можно узнать о web workers. Для наших целей этого достаточно, и мы будем использовать именно это. Если вы хотите узнать больше, обратитесь к документации на сайте Mozilla Developer Network.
Получив эти компоненты, мы можем реализовать надежное и удобное соединение с нашими web workers, применяя шаблоны проектирования. Перед этим нам необходимо концептуально изучить еще два шаблона: Business Delegate и Dispatcher.
Шаблон Business delegate
Этот шаблон используется для того, чтобы скрыть сложность доступа к бизнес-сервисам или бизнес-слою от клиента или презентационного слоя, предоставляя единую точку доступа с хорошо определенным и простым интерфейсом.
Его можно рассматривать как вариант или развитие шаблонов Proxy и Decorator, рассмотренных в главе 2, Принципы и шаблоны проектирования ПО, но в более широком логическом масштабе между архитектурными слоями. Обычно он включает в себя как минимум следующие сущности:
- Сущность Business delegate, которая выступает в качестве единой точки входа клиента во все доступные сервисы
- Сущность Business LookUp или Router, функция которой состоит в том, чтобы направить выполнение входящего запроса к соответствующему сервису
- Business services, службы, которые предоставляют общий интерфейс (напрямую или через прокси-шаблон) с предоставляемым ими функционалом
Для наших целей этот шаблон можно представить в виде следующей диаграммы:
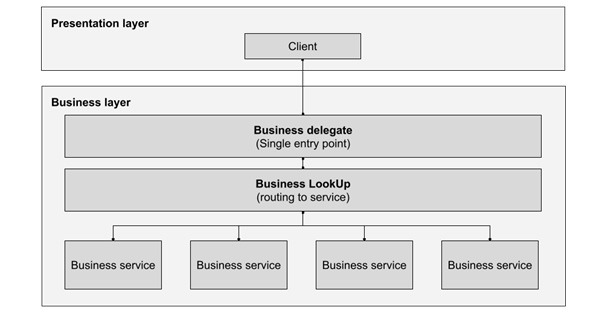
Рисунок 8.4 - Представление шаблона Business delegate
Этот шаблон может быть применен на нескольких архитектурных уровнях. В нашем конкретном случае мы хотим применить его к нашему приложению с web workers.
В качестве презентационного слоя мы будем рассматривать родительский процесс, а в качестве бизнес-слоя - web worker. В родительском (или главном) процессе, как обычно, будет находиться наше приложение Vue, ориентированное в первую очередь на обеспечение отличного пользовательского опыта.
Процесс web worker будет отвечать за предоставление нам доступа к сервисам, либо локальным, как в случае с IndexedDB, либо удаленным, инкапсулируя связь с нашим сервером и дополнительными сервисами, а также любые дополнительные вычислительноемкие функции.
Такое разделение задач имеет множество преимуществ, причем не только с точки зрения производительности, но и с точки зрения проектирования и реализации приложения в целом.
Перед тем как приступить к реализации кода для этой главы, необходимо рассмотреть еще один шаблон, который мы будем реализовывать, поскольку мы можем передавать между процессами только сериализуемые данные и не можем выполнять вызовы функций, как это предлагает обычный шаблон Business delegate. Мы расширим идею шаблона Command и будем использовать так называемый шаблон Dispatcher.
Шаблон Dispatcher
Ранее мы видели, что родительский процесс или рабочий веб-процесс могут инициировать взаимодействие, отправляя друг другу сообщение. Если определен соответствующий слушатель (onmessage), то любой из них может получать эти события и реагировать на них.
В шаблоне Dispatcher эти сообщения содержат информацию, связанную с событием, - например, данные. Ключевым фактором, определяющим этот шаблон проектирования, является то, что сообщения о событиях должны публиковаться между потоками и планироваться для выполнения по их приходу. Разумеется, такое планирование может включать и "немедленное выполнение" некоторой задачи или функции.
Реализация этого шаблона довольно тривиальна, и можно считать, что он сродни шаблону Command, который мы рассматривали в главе 2, Принципы и шаблоны проектирования программного обеспечения, поэтому больше мы его рассматривать не будем. Вместо этого мы воспользуемся концепциями взаимодействия между потоками, планирования и событий с данными, чтобы создать наше решение для работы с web workers.
Установка конвейера взаимодействия с веб-рабочим
Теперь мы рассмотрели ключевые концепции, которые мы хотим применить в нашей реализации взаимодействия с web workers для нашего Vue-приложения. Эту модель можно использовать многократно от приложения к приложению и совершенствовать по мере необходимости. В качестве общего плана действий вот что мы построим, используя рассмотренные ранее шаблоны проектирования:
- Мы создадим web worker с единой точкой доступа в нашем приложении Vue, следуя шаблону Business Delegate
- Каждое сообщение будет вызывать событие для любого процесса (родитель-работник или работник-родитель) и включать данные о команде и полезной нагрузке, а также информацию об отслеживании для планирования, как в шаблоне Dispatcher
Достаточно простая архитектура, описанная в предыдущих пунктах, позволяет организовать рабочий процесс, как показано здесь:
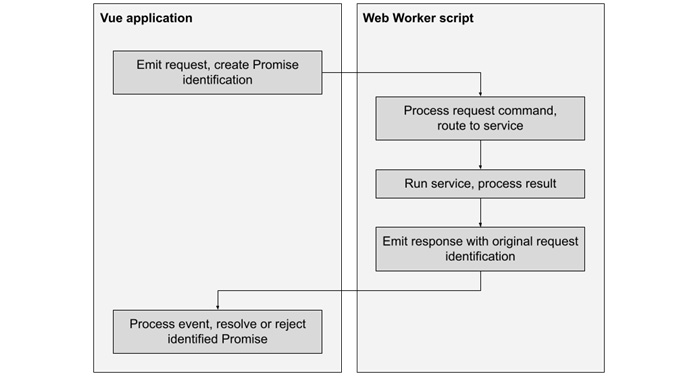
Рисунок 8.5 - Реализация коммуникационного процесса с web worker
Теперь, когда у нас есть теоретическая база и общее представление о том, что мы будем создавать, пришло время перейти к коду. Мы остановимся на наиболее актуальных частях кода, реализующих упомянутую ранее модель. Чтобы увидеть весь код приложения, пожалуйста, ознакомьтесь с полным исходным кодом из репозитория GitHub.
Начнем с создания сервиса, который будет нашей точкой входа в клиентское приложение:
./services/WebWorker.js
import WebWorker from "../webworker/index.js?worker"
const _worker = new WebWorker() //1
const service = {
queue: {}, //2
request(command, payload = {}) { //3
return new Promise((resolve, reject) => { //4
let message = {
id: crypto.randomUUID(),
command,
payload
}
service.queue[message.id] = {resolve, reject} //5
_worker.postMessage(message); //6
})
}
processMessage(data) {
let id = data.id
if(data.success){
service.queue[id].resolve(data.payload) //7
} else {
service.queue[id].reject(data.payload)
}
delete service.queue[id]; //8
}
}
_worker.onmessage = (event) => {
service.processMessage(event.data); //9
}
export default service; //10Эта реализация проста, но эффективна. Она хорошо помогает нам понять, как работают эти шаблоны. Начнем с импорта конструктора web worker с использованием специального суффикса Vite worker и последующего создания ссылки на экземпляр в строке //1. Как обычно, этот сервис будет синглтоном, поэтому мы создаем его как объект JavaScript, который экспортируем позже в строке //10. У сервиса всего три свойства:
- queue: Он определяется в строке //2 и представляет собой словарь, который мы будем использовать для хранения запланированных обращений к web worker с использованием уникального идентификатора. В каждой записи будет храниться ссылка на методы разрешения обещания (resolve и reject).
- request() метод: Определенный здесь в строке //3, он будет использоваться другими сервисами и компонентами ("клиентами") для запроса задач у web worker. Он всегда возвращает Promise (строка //4). Сообщение, передаваемое web workerу, инкапсулирует command и payload, полученные в качестве параметров, с уникальным идентификатором. Мы сохраняем ссылки на методы resolve() и reject() в queue (строка //5), и, наконец, используя собственный метод обмена сообщениями web worker, публикуем сообщение в строке //6.
- processMessage() метод: Здесь мы получаем данные, переданные web workers, и на основании идентификации и результата операции, переданного в атрибуте .success (Boolean), обращаемся к queue и либо используем функцию resolve(), либо reject(), чтобы разрешить или отклонить обещание (строка //7). Наконец, мы удаляем ссылку из queue в строке //8.
Последним шагом в этом файле является связывание входящих сообщений, передающих данные непосредственно из web worker в service.processMessage() в строке //9. Теперь, наверное, понятно, что мы приняли некоторые решения относительно структуры сообщения, а также ответа. Сообщения состоят из трех компонентов: id, command и payload. Ответы также состоят из трех элементов: id, success и payload. На стороне клиента мы решили оперировать Promise-ами, так как они не имеют "тайм-аута".
После того как с клиентской частью разобрались, пришло время поработать над сценарием web worker. Создайте следующий файл index.js в каталоге webworker:
./webworker/index.js
import testService from "./services/test"
const services = [testService] //1
function sendRequest(id, success=false, payload={}) {
self.postMessage({id, success, payload}) //2
}
self.onmessage=(event) => { //3
const data = event.data;
services.forEach(service => { //4
if (service[data.command]) { //5
service[data.command](data.payload) //6
.then(result => {
sendRequest(data.id, true, result) //7
}, err => {
sendRequest(data.id, false, err)
})
}
})
}Web worker стал еще короче, и мы также приняли некоторые решения относительно интерфейса, реализуемого каждым базовым сервисом: каждый из их методов должен возвращать Promise. Давайте посмотрим код и выясним, почему.
Начнем со строки //1 с импорта testService (мы создадим его позже) и включим его в массив сервисов. Это облегчит добавление новых сервисов путем их импорта и включения в этот массив (это может стать ступенькой к архитектуре плагинов, но пока мы останемся простыми).
Затем мы определяем глобальную функцию sendRequest(), которая будет отправлять родительскому процессу закодированное сообщение с тремя полями: id, success и payload, как и ожидает клиент в данном порядке. Вот что происходит в строке //2.
В строке //3 мы определяем обработчик события onmessage для обработки входящих сообщений. При получении одного из них мы обращаемся к массиву services в поисках подходящей команды (строка //4), а когда находим (строка //5), то выполняем функцию, передавая в качестве параметра полезную нагрузку (строка //6) после ее разбора с помощью утилиты JSON.
Затем, разрешив или отклонив Promise, мы передаем клиенту соответствующий результат в строке //7. Этот короткий фрагмент кода выполняет роль делегатора и диспетчера. Наконец, давайте посмотрим на testService, чтобы увидеть, как он работает:
./webworker/services/test.js
const service = {
test() {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve("Web worker жив и работает!")
}, 3000)
})
}
}
export default service;Как вы можете оценить, этот тестовый сервис не делает ничего особенного, кроме как возвращает Promise и устанавливает таймер на его разрешение через 3 секунды. Эта задержка является искусственной, поскольку в противном случае ответ был бы немедленным. Если запустить пример приложения, то при нажатии на кнопку Send request можно увидеть, как через 3 секунды сообщение изменится с Ожидание... на Web worker жив и работает!, как и ожидалось:
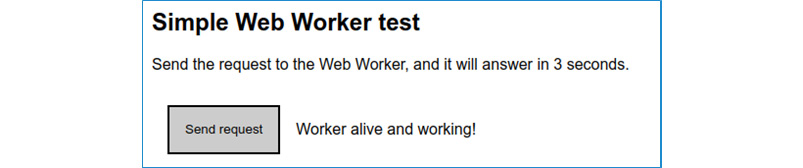
Рисунок 8.6 - Тестовое приложение отправляет команду рабочему и показывает результат
Для этого в компоненте App.vue мы импортируем наш сервис web worker и отправляем запрос со строкой command в качестве имени функции в сервисе, которую мы хотим выполнить. Для данного примера добавим следующий код:
import webWorker from "./services/WebWorker.js"
webWorker.request("test").then(data => {...}, err => {...})Эти простые строки кода для создания и управления веб-воркером обеспечивают приложению значительный прирост вычислительной мощности и производительности. Теперь, когда все готово, пришло время сделать что-то более существенное с нашим web worker. Давайте обеспечим ему доступ к нашей локальной базе данных и к сети.
Получение доступа к IndexedDB с помощью DexieJS в web worker.
IndexedDB - это очень мощная база данных типа "ключ-значение", однако ее собственная реализация предоставляет API, с которым довольно сложно работать. Фактически рекомендуется не использовать его, а работать с ним через фреймворк или библиотеку.
Движок базы данных быстр и очень податлив, поэтому на его основе создано множество библиотек, воссоздающих функции и возможности, отсутствовавшие изначально. Некоторые библиотеки даже имитируют SQL и базы данных на основе документов (document-based). Среди доступных и свободно используемых библиотек можно назвать следующие:
- DexieJS: Очень быстрая и хорошо документированная библиотека, реализующая NoSQL-базу данных на основе документов.
- PouchDB: База данных, имитирующая функциональность CouchDB от Apache и обеспечивающая встроенную синхронизацию с удаленными серверами.
- RxDB: Это база данных, реализующая реактивную модель. Она также поддерживает репликацию в CouchDB.
- IDB: Это легкая реализация обертки поверх API IndexedDB с некоторыми изменениями для улучшения удобства использования.
В зависимости от ваших требований к локальному хранилищу, вам подойдут эти или другие варианты. В данном примере мы будем использовать DexieJS, поскольку он хорошо документирован и может похвастаться впечатляющей скоростью выполнения массовых операций.
Мы расширим наш предыдущий пример и создадим однокомпонентное мини-приложение для хранения, извлечения, удаления и просмотра заметок. Здесь рассматриваются самые основные операции создания, чтения, обновления и удаления (CRUD). При выполнении кода примера он будет выглядеть примерно так:

Рисунок 8.7 - Пример однокомпонентного CRUD.
В данном примере можно создавать новые заметки, просматривать ранее сохраненные (они будут постоянными в зависимости от домена), выделять их для просмотра текста, а также удалять. Все операции будут выполняться в web worker. Давайте включим Dexie в наше приложение с помощью npm:
$ npm install dexieСледующим шагом создадим наш пример компонентного приложения:
/src/components/DbNotes.vue
<script setup>
import webWorker from "../services/WebWorker" //1
import { ref } from "vue"
const _notes=ref([]),_note=ref({}),_selected=ref({}) //2
loadNotes()
function saveNote(){ //3
if(_note.value.title && _note.value.text){
webWorker
.request("addNote", JSON.stringify(_note.value))
.then(id => {loadNotes()}, err=>{...})
.finally(() => {_note.value={}})
}
}
function deleteNote(id){ //4
WebWorker
.request("deleteNote", {id})
.finally(() => {loadNotes()})
}
function openNote(note){_selected.value=note;} //5
function loadNotes(){ //6
webWorker
.request("getNotes",[])
.then(data => {_notes.value=data;}
() => {_notes.value=[]})
}
</script>
<template>
<div>
<section>
<h3>New note</h3>
<input type="text"
v-model="_note.title"
placeholder="Title"/>
<textarea v-model="_note.text"
placeholder="Note text..."></textarea>
<button @click="saveNote()">Save</button>
</section>
<section>
<h3>Notes</h3>
<div v-for="n in _notes" :key="n.id">
<a @click="openNote(n)">{{ n.title }}</a>
<a @click="deleteNote(n.id)">[X]</a>
</div>
</section>
<section>
<h3>Selected note</h3>
<strong>{{ _selected.title }}</strong>
<p>{{ _selected.text }}</p>
</section>
</div>
</template>Файл выше очищен от CSS стилей и других элементов оформления, поэтому мы можем сосредоточиться на активных частях кода, реализующих изучаемые операции. Мы начинаем с импорта нашего класса сервиса для работы с web worker в строке //1 и создания нескольких внутренних реактивных переменных в строке //2.
Мы будем использовать _notes для хранения полного списка заметок, извлеченного из базы данных, _note в качестве заполнителя для создания новых заметок, и _selected для отображения заметки, на которую был сделан щелчок в списке.
Вы можете найти CRUD-операции в каждой функции (строки с //3 по //6) и заметите, что они очень похожи, за исключением работы с реактивными элементами пользовательского интерфейса. Они просто собирают необходимую информацию для создания запроса к web worker и затем применяют результат.
Однако обратите внимание, что в функции saveNote(), когда нужно передать объект, описывающий нашу новую заметку, мы клонируем реактивное значение Vue. Это связано с тем, что реализация прокси, которую Vue использует для работы с реактивностью, не является сериализуемой, поэтому, если мы не создадим копию обычного объекта или не применим другие подобные техники для извлечения значений, связь с web worker будет нарушена и выдаст ошибку.
Простой способ убедиться в том, что объект данных предоставляется в виде клонируемого объекта, - преобразовать его в строку с помощью JSON.stringify(_note.value), как в нашем коде (можно также создать непосредственно клон, используя JSON.parse(JSON.stringify(_note.value)).
Необходимо помнить о том, как будет передаваться информация, чтобы она могла быть правильно обработана на принимающей стороне web worker. Сейчас это станет очевидным, когда мы увидим dbService.js в web worker:
./src/webworker/services/dbService.js
import Dexie from "dexie"
const db = new Dexie("Notes") //1
db.version(1).stores({notes: "++id,title"}); //2
const service = {
addNote(note={}) { //3
return new Promise(async (resolve, reject)=>{
try{
let result_id=await db.notes.add(JSON.parse(note)) //4
resolve({id:result_id})
}catch(err){reject({})}
})},
getNotes(){
return new Promise(async (resolve, reject)=>{
try{
let result=await db.notes.toArray(); //5
resolve(result)
}catch{reject([])}
})},
deleteNote({id}){
return new Promise(async (resolve, reject)=>{
try{
await db.notes.delete(id) //6
resolve({})
}catch{reject({})}
})}}
export default service;Для использования Dexie мы сначала импортируем конструктор, как в строке //1, и создаем новую базу данных с именем Notes. Прежде чем приступить к ее использованию, необходимо определить версию и простую схему таблиц/коллекций с полями, которые будут индексироваться.
Это и происходит в строке //2, где мы определяем коллекцию notes с двумя индексируемыми полями: id и title. Эти индексированные поля передаются в виде строки, разделенной запятыми по именам полей.
Мы также включили двойной знак плюс в качестве префикса для поля id. Благодаря этому поле автоматически генерируется базой данных и автоматически увеличивается с каждой новой записью.
Следующая важная функция, addNote(), добавляет запись в коллекцию notes. Поскольку мы передаем данные, сериализуя объект в виде строки, в нашем компоненте в строке //4 необходимо разобрать строку, чтобы перекомпоновать объект.
В функции getNotes() мы просто извлекаем все элементы из коллекции и используем метод toArray(), предоставляемый Dexie, который преобразует их в массив JavaScript (строка //5). Таким образом, мы сможем вернуть его непосредственно в качестве результата для разрешения обещания.
Последнее замечание по этому коду касается метода deleteNote(): в строке //6 мы не перехватываем результат асинхронной операции. Это связано с тем, что данная операция не возвращает полезного значения. В данном случае эта операция всегда будет разрешаться, если только ошибка движка базы данных не прервет ее выполнение.
Важно помнить, что ошибки на web worker не повлияют на родительский процесс, и любые операции в нем не будут затронуты.
После того как мы создали службу, пришло время немного изменить индексный файл web worker. Добавьте следующие строки:
./src/webworker/index.js
import dbService from "./services/dbService";
const services = [dbService, testService];Других изменений в этом файле не требуется. Как видим, для реализации CRUD-операций на web worker требуется не так уж много. Несмотря на то, что их можно выполнять в родительском процессе, а также на небольшой штраф за межпроцессное взаимодействие, выигрыш в производительности значителен и вполне оправдывает затраченные усилия.
Особенно если наше приложение включает в себя фоновые процессы, такие как синхронизация с удаленным сервером, то они должны выполняться веб-рабочим. Далее рассмотрим, как можно получить доступ к сети и использовать Representational State Transfer API (RESTful API) также из web worker.
Одним из наиболее распространенных применений сетевых API сегодня в веб-разработке является реализация RESTful API. Это протокол, в котором каждое сообщение не имеет статистики и представляет собой тип действия, требуемого в месте назначения. Протокол HTTP, используемый в Интернете, идеально подходит для такого типа API, поскольку каждый сетевой вызов раскрывает метод, определяющий тип требуемой операции:
- Операции GET позволяют получать данные и файлы
- Операции PUT обновляют данные
- Операции POST создают новые данные на сервере
- Операции DELETE удаляют данные на сервере
Легко заметить, что эти методы соответствуют операциям CRUD, поэтому, сделав соответствующий сетевой вызов, сервер знает, как обработать данные, полученные в соответствующей конечной точке. Существует множество стандартов, используемых для форматирования данных, передаваемых между конечными точками. В частности, одним из наиболее распространенных является формат JSON, который мы так удобно используем в JavaScript.
Работа с асинхронными вызовами с помощью собственной реализации в браузере, как минимум, громоздка, но не невозможна. В целях практичности и безопасности рекомендуется использовать известную библиотеку, например Axios. Для установки библиотеки необходимо выполнить в терминале следующую команду:
$ npm install axiosЧерез несколько мгновений библиотека будет установлена в наш проект в качестве зависимости. Библиотека предоставляет очень удобные методы для запуска сетевых вызовов для каждого метода HTTP. Например, axios.get выполняет запрос GET, axios.post - запрос POST и т.д.
В рамках учебного упражнения мы реализуем простую службу, которая будет выполнять сетевые вызовы на удаленный сервер из web worker. Для простоты мы создадим только два метода:
./webworker/services/network.js
import axios from "axios"
axios.defaults.baseURL="http://localhost:3000"
const service = {
GET(payload={}) {
return new Promise((resolve, reject)=>{
axios
.get(payload.url,{params:{data:payload.data}})
.then(result=>{
if(result.status>=200 && result.status<300){
resolve(result.data)
} else {reject()}
}).catch(()=>{reject()})
})},
POST(payload={}) {
return new Promise((resolve, reject)=>{
axios
.post(payload.url,{data:payload.data})
.then(result=>{
if(result.status>=200 && result.status<300){
resolve(result.data)
} else {reject()}})
.catch(()=>{reject()})
})}}
export default service;Этот сервис достаточно прост. В промышленном приложении он будет являться промежуточным звеном для обслуживания других сервисов. В данном примере реализовано всего два метода, соответствующих методам HTTP-запроса. Обратите внимание, что они очень похожи, меняется только название метода и сигнатура некоторых параметров. Первым параметром всегда является конечная точка (URI) для подключения.
Второй параметр - это либо данные, либо объект с опциями. О том, как обрабатывать каждый конкретный запрос и решать крайние случаи, я отсылаю вас к официальной документации.
Следует отметить, что в начале файла мы задаем домен по умолчанию для всех остальных сетевых вызовов. Таким образом, мы избегаем его повторения в каждом вызове. С помощью этой библиотеки мы можем легко задавать специфические HTTP-заголовки и опции, например JSON Web Tokens для аутентификации, о чем мы рассказывали в главе 5, Одностраничные приложения, когда упоминали различные методы аутентификации.
Чтобы включить этот сервис в наш web worker, мы импортируем его и добавим в массив services, как мы это делали ранее. Изменим начало этого файла так, чтобы оно выглядело следующим образом:
./webworker/index.js
import netService from "./services/network"
const services = [dbService, netService, testService]С этим новым включением наш web worker готов. Теперь мы реализуем один компонент для тестирования взаимодействия, и он будет выглядеть следующим образом:

Рисунок 8.8 - Простой тест, в котором сервер зеркально отражает отправленную информацию.
Наш компонент позволяет выбрать метод HTTP-запроса (GET или POST) и отправить произвольные данные. Тестовый сервер будет просто зеркально отражать полученные данные обратно клиенту, где компонент будет отображать их на экране. Реализация достаточно проста:
./src/components/NetworkCommunication.vue
<script setup>
import webWorker from "../services/WebWorker"
import { ref } from "vue"
const
_data_to_send = ref(""),
_data_received = ref(""),
_method = ref("GET")
function sendData(){
webWorker
.request(_method.value, //1
{url:"/api/test", data: _data_to_send.value})
.then(reply=>{_data_received.value=reply},
()=>{_data_received.value="Error"
})
}
</script>
<template>
<div>
<section>
<h4>Текст для отправки</h4>
<div>
<label>
<input
type="radio"
value="GET"
name="method"
v-model="_method">
<span>GET Method</span>
</label>
<label>
<input
type="radio"
value="POST"
name="method"
v-model="_method">
<span>POST Method</span>
</label>
</div>
<input type="text" v-model="_data_to_send">
<button @click="sendData()">Send</button>
</section>
<section>
<h4>Данные получены с сервера</h4>
{{ _data_received }}
</section>
</div>
</template>В этом компоненте мы импортируем сервис webWorker и объявляем три реактивные переменные для отправки и получения данных и одну для хранения выбранного метода для выполнения запроса. Наш простой тестовый сервер будет получать запрос и просто зеркально отражать данные, которые мы отправляем. Позже мы рассмотрим, как создать этот простой сервер с помощью Node.js.
В шаблоне пользователь может выбрать тип отправляемого запроса (GET или POST), этот выбор мы сохраняем в переменной _method. Это значение мы используем в качестве команды, передаваемой рабочему в строке //1. В качестве полезной нагрузки мы передаем данные в виде объекта-члена. Когда обещание разрешается, мы сохраняем значение из ответа в переменной _data_received.
Остальная часть исходного кода должна быть тривиальна для понимания, так как в ней рассматривается в основном шаблон и представление информации на экране. Прежде чем закончить эту главу, давайте посмотрим, как тестовый сервер может быть реализован с помощью Node.js.
Простой NodeJS-сервер для тестирования
Для тестирования сетевых взаимодействий нам представляется целесообразным реализовать небольшой сервер на Node.js для реализации конечных точек, которые мы тестируем. В отдельной директории от нашего приложения Vue откроем окно терминала и введем следующую команду:
$ npm initМастер командной строки задаст несколько вопросов для создания файла package.json, который представляет собой приложение Node.js. После этого выполните эту команду для установки зависимости Express.js, которая предоставит нам фреймворк для создания веб-сервера:
$ npm install express corsПосле завершения процесса создайте файл index.js со следующим кодом:
./server/index.js
const express = require("express") //1
const cors = require("cors") //2
const app = express() ; //3
const PORT = 3000
app.use(cors()) //4
app.use(express.json()) //5
app.get("/api/test", (req, res)=>{ //6
const data = req.query //7
res.jsonp(data) //8
})
app.post("/api/test", (req, res)=>{
const data = req.body //9
res.jsonp(data)
})
app.listen(PORT, ()=>{ //10
console.log("Server listening on port " + PORT)
})С помощью этих нескольких строк кода мы можем запустить небольшой сервер, принимающий и отвечающий на запросы в формате JSON. Мы импортируем конструктор express (строка //1), а также плагин (строка //2). Это важно для того, чтобы мы могли обращаться к этому серверу с любого домена (origin).
Cross-Origin Request Sharing (CORS) служит для обхода мер безопасности, применяемых серверами для предотвращения обслуживания запросов из других источников (origins), кроме своего собственного. Чтобы разрешить запросы из других источников, его необходимо включить.
После создания серверного приложения (строка //3) мы передаем плагин (строка //4). Также мы передаем еще один плагин (строка //5), чтобы сервер идентифицировал и отвечал на сетевые вызовы с помощью JSON-объектов. Далее мы создаем две конечные точки, одну для GET запросов (строка //6) и вторую для POST запроса.
Первый параметр - это URL, по которому сервер будет прослушивать обращения. В данном случае они одинаковы, так как единственным отличием будет тип метода запроса. Это стандартная практика.
Каждая конечная точка получает в качестве последнего аргумента функцию обратного вызова, имеющую не менее двух параметров: req (запрос) и res (ответ). Эти объекты содержат методы и информацию о полученном запросе, а также необходимые методы для создания ответа клиенту.
Для запросов GET полученные данные передаются вместе с URL в виде "строки запроса", поэтому для доступа к ним Express красиво упаковывает их в виде объекта в поле request.query (строка //7).
Поскольку мы просто отвечаем теми же полученными данными, в строке //8 мы используем объект res для создания дополненного JSON-ответа с тем же объектом данных. Мы делаем это потому, что считаем, что можем получать вызовы из любого домена (поскольку включили CORS), и хотим быть уверены, что ответ будет полностью понятен. JSON with Padding (JSONP) - это метод отправки ответа с помощью другого метода. Нам не нужно беспокоиться об этом, так как оба конца (отправитель и получатель) обрабатываются сервером Express и клиентом Axios.
В методе post разница заключается в том, что данные содержатся в теле сообщения (строка //9), отсюда и разная обработка. Наконец, сервер начинает прослушивать указанный порт (строка //10). Теперь мы можем обращаться к серверу по адресу http://localhost:3000/, который мы настроили в нашей сетевой службе как адрес по умолчанию для Axios.
В результате мы получили возможность работать с сервером по адресу http://localhost:3000/.
После создания этого сервера мы можем провести полное тестирование всех частей системы.
Подведение итогов
В этой главе мы рассмотрели несколько очень важных концепций, позволяющих кардинально улучшить архитектуру и производительность нашего приложения. Web workers - это удивительная технология, позволяющая веб-приложениям использовать преимущества современных аппаратных архитектур и современных операционных систем.
С точки зрения стационарности, многопоточность с использованием web workers не требует особых дополнительных усилий и сложностей, а выигрыш от ее применения весьма ощутим. Мы также увидели, как использовать web workers для доступа к сетевым сервисам, а также к локальной постоянной базе данных, предоставляемой браузером (IndexedDB).
Мы познакомились еще с двумя шаблонами проектирования для реализации масштабируемой архитектуры нашего приложения и проверили их концепции и реализацию на примере простых компонентов и сервисов. Использование web workers значительно повышает производительность и качество выполнения хорошо спроектированного веб-приложения.
В следующей главе мы рассмотрим инструменты и методы автоматического тестирования нашего кода, обеспечивающие соответствие отдельных его частей своему назначению в соответствии со спецификациями и требованиями к программному обеспечению.
Вопросы для проверки
- Какие ограничения JavaScript могут повлиять на производительность веб-приложения?
- Что такое web workers? Каковы их ограничения?
- Как приложения Vue могут взаимодействовать с web workers?
- Какие преимущества дает использование такого шаблона проектирования, как Business delegate, для работы с web workers?
- Что можно изменить в коде примера, чтобы управлять несколькими web workers, а не одним? В каких случаях, по вашему мнению, это целесообразно?